What happens in the brain when we feel threatened? Answers to this question could lead to new treatments for people with anxiety and panic disorders and PTSD. Caltech neuroscientist Dean Mobbs (http://www.hss.caltech.edu/people/dean-mobbs) studies how the brain processes different types of danger. In this video, Mobbs talks about fear, horror, and hope. Participants in his studies play virtual-predator video games inspired by horror movies while fMRI machines track the activity in their brains as they encounter threats. Mobbs and his research group recently showed that two regions of the brain are involved in processing fear: one for distant threats that allow some time to strategize, and one for immediate danger that requires a fight, flight, or freeze response. (Read more: https://www.caltech.edu/about/news/you-dont-think-your-way-o…tack-81542)
Mobbs conducts research in the Caltech Brain Imaging Center (http://cbic.caltech.edu), which is part of the Tianqiao and Chrissy Chen Institute for Neuroscience at Caltech (http://neuroscience.caltech.edu). Founded with a $115 million gift to Break Through: The Caltech Campaign (https://breakthrough.caltech.edu/) from visionary philanthropists Tianqiao Chen and Chrissy Luo, the Chen Institute at Caltech supports researchers who are deepening our understanding of the brain.
Contrary to existing antimicrobial coatings, which function by eliminating microorganisms upon contact over some adequate duration of time, the technology developed by FendX takes a preventative approach. Utilizing nanotechnology to develop film and spray protective coatings that prevent microbial adherence to surfaces, thereby minimizing the potential for transmission. This is a significant departure from reactive coating surfaces in the market, offering a proactive method for reducing the occurrence and spread of HAIs.
REPELWRAP™ film, is FendX’s lead product in development and is with their manufacturer who is gearing up to conduct pilot runs on their commercial manufacturing line to create intermediate films for testing. FendX is also developing a spray-based product using their patent-pending nanotechnology. This spray offers the same preventative measures against microbial adherence and has the potential to be more versatile and easier-to-apply to surfaces. It not only demonstrates the same repelling properties but also effectively inactivates any residual microorganisms on the coated surface.
FendX is focused on healthcare settings, but is also exploring potential applications in other multiple billion high-traffic industries. It is anticipated that FendX’s future protective coatings can be applied to various high-touch surfaces: from bed rails and IV poles in healthcare to potential handrails in public transport systems to door handles in restaurants and public bathrooms. Given that the technology inhibits microbial adherence, it has the potential to significantly reduce the spread of pathogens in virtually any setting where human interaction with surfaces occurs. This broad applicability signifies that the market opportunity could be vastly larger than the projected $7.6 billion for antimicrobial coatings by 2025, opening doors to various industries and settings.
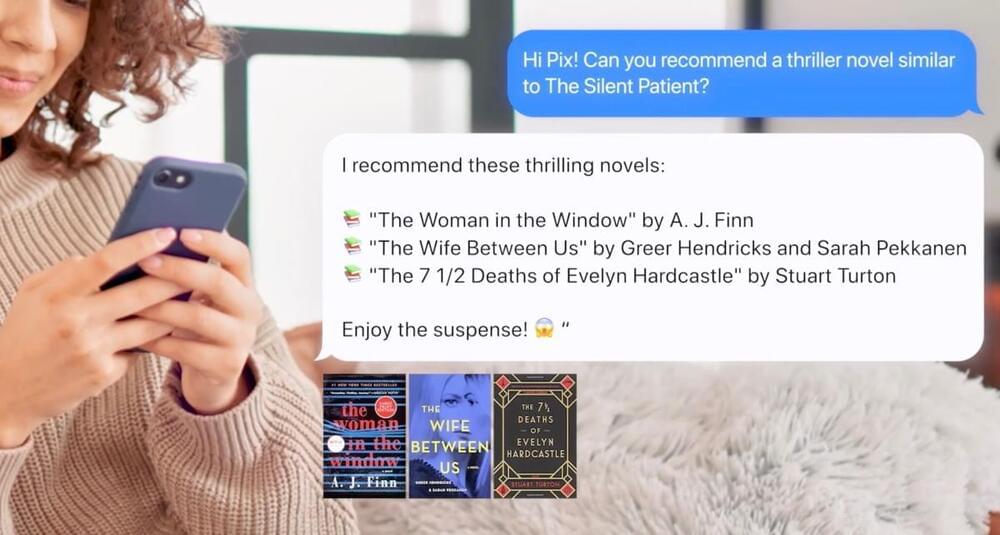
Likewise, the company behind an app that can recommend your next TV binge, movie to watch, podcast to stream or book to read, is out today with its own entertainment-focused AI companion, Pix. Built using a combination of Likewise’s own customer data and technology from partner OpenAI, Pix can make entertainment recommendations and answer other questions via text message or email, or by communicating with Pix within the Pix mobile app, website or even by speaking to Pix’s TV app using a voice remote.
Founded in 2017 by former Microsoft communications chief Larry Cohen with financial backing from Bill Gates, the recommendations startup aims to offer an easy way for people to discover new TV shows, movies, books, podcasts and more, as well as follow other users and make lists of their favorites to share. While today, recommendations are often baked into the streaming services or apps we use to play our entertainment content, Likewise maintains a registered user base of more than 6 million, and over 2 million monthly active users.
To build Pix, the company leveraged around 600 million consumer data points along with machine learning algorithms, as well as the natural language processing technology of OpenAI’s GPT 3.5 and 4. To work, the AI chatbot learns the preferences of the individual user and then provides them with personalized recommendations — similar to Likewise itself. In addition, the bot will reach out to users when new content becomes available that matches their interests.
The instrumental title track “I Robot”, together with the successful single “I Wouldn’t Want To Be Like You”, form the opening of “I Robot”, a progressive rock album recorded by The Alan Parsons Project and engineered by Alan Parsons and Eric Woolfson in 1977. It was released by Arista Records in 1977 and re-released on CD in 1984 and 2007. It was intended to be based on the “I, Robot” stories written by Isaac Asimov, and actually Woolfson spoke with Asimov, who was enthusiastic about the concept. However, as the rights had already been granted to a TV/movie company, the album’s title was altered slightly by removing the comma, and the theme and lyrics were made to be more generically about robots rather than specific to the Asimov universe. The cover inlay reads: “I ROBOT… HE STORY OF THE RISE OF THE MACHINE AND THE DECLINE OF MAN, WHICH PARADOXICALLY COINCIDED WITH HIS DISCOVERY OF THE WHEEL… ND A WARNING THAT HIS BRIEF DOMINANCE OF THIS PLANET WILL PROBABLY END, BECAUSE MAN TRIED TO CREATE ROBOT IN HIS OWN IMAGE.” The Alan Parsons Project were a British progressive rock band, active between 1975 and 1990, founded by Eric Woolfson and Alan Parsons. Englishman Alan Parsons (born 20 December 1948) met Scotsman Eric Norman Woolfson (18 March 1945 — 2 December 2009) in the canteen of Abbey Road Studios in the summer of 1974. Parsons had already acted as assistant engineer on The Beatles’ “Abbey Road” and “Let It Be”, had recently engineered Pink Floyd’s “The Dark Side Of The Moon”, and had produced several acts for EMI Records. Woolfson, a songwriter and composer, was working as a session pianist, and he had also composed material for a concept album idea based on the work of Edgar Allan Poe. Parsons asked Woolfson to become his manager and Woolfson managed Parsons’ career as a producer and engineer through a string of successes including Pilot, Steve Harley, Cockney Rebel, John Miles, Al Stewart, Ambrosia and The Hollies. Parsons commented at the time that he felt frustrated in having to accommodate the views of some of the musicians, which he felt interfered with his production. Woolfson came up with the idea of making an album based on developments in the film industry, where directors such as Alfred Hitchcock and Stanley Kubrick were the focal point of the film’s promotion, rather than individual film stars. If the film industry was becoming a director’s medium, Woolfson felt the music business might well become a producer’s medium. Recalling his earlier Edgar Allan Poe material, Woolfson saw a way to combine his and Parsons’ respective talents. Parsons would produce and engineer songs written by the two, and The Alan Parsons Project was born. This channel is dedicated to the classic rock hits that have become part of the history of our culture. The incredible AOR tracks that define music from the late 60s, the 70s and the early 80s… lassic Rock is here!
Reality is a tricky thing. Is love real? What about the number 5? This is clearly a job for a philosopher, and James Ladyman is one of the world’s acknowledged experts. He and his collaborators have been championing a view known as “structural realism,” in which real things are those that reflect true, useful patterns in the underlying reality. We talk about that, but also about a couple of other subjects in the broad area of philosophy of science: the history and current status of materialism/physicalism, and the nature of complex systems. This is a deep one.
James Ladyman obtained his Ph.D. from the University of Leeds, and is currently a Professor of Philosophy at the University of Bristol. He has worked broadly within the philosophy of science, including issues of realism, empiricism, physicalism, complexity, and information. His book Everything Must Go (co-authored with Don Ross) has become an influential work on the relationship between metaphysics and science.
Fascinating… when can we expect this to be invented?
A short film set in the near future, where augmented reality has become so ubiquitous that the line between the real and virtual worlds have become blurred. When a new, dangerous technology is created that can manipulate the perception of this brave new world, who will exploit it? Who will monetize it? Who will become twisted by it?
“Augmented” by Ross Peacock.
More About “Augmented”: Augmented is directed by Ross Peacock and produced by Ben Mortimer of Black Arrow Pictures, and executive produced by Tim Clayton of Sweet Potato Productions. Starring Sabine Crossen, Brett Fancy and Camilla Roholm.
The company making the film; Brightburn 2 will be using AI and other technologies for its film making process.
EXCLUSIVE: The duo behind Brightburn producer The H Collective are launching H3 Entertainment, a company they say will look to integrate the Metaverse, Web3 and AI into a slate of films.
According to its founders Mark Rau and Kent Huang, at a time of industry sensitivity around the use of AI, the model will “respect professionals and fans while promoting responsible technology integration”.
The H-Collective’s projects to date have included 2019 horror movie Brightburn, starring Elizabeth Banks, which it produced with James Gunn and which was picked up by Screen Gems, and The Parts You Lose, starring Aaron Paul and produced by Mark Johnson.