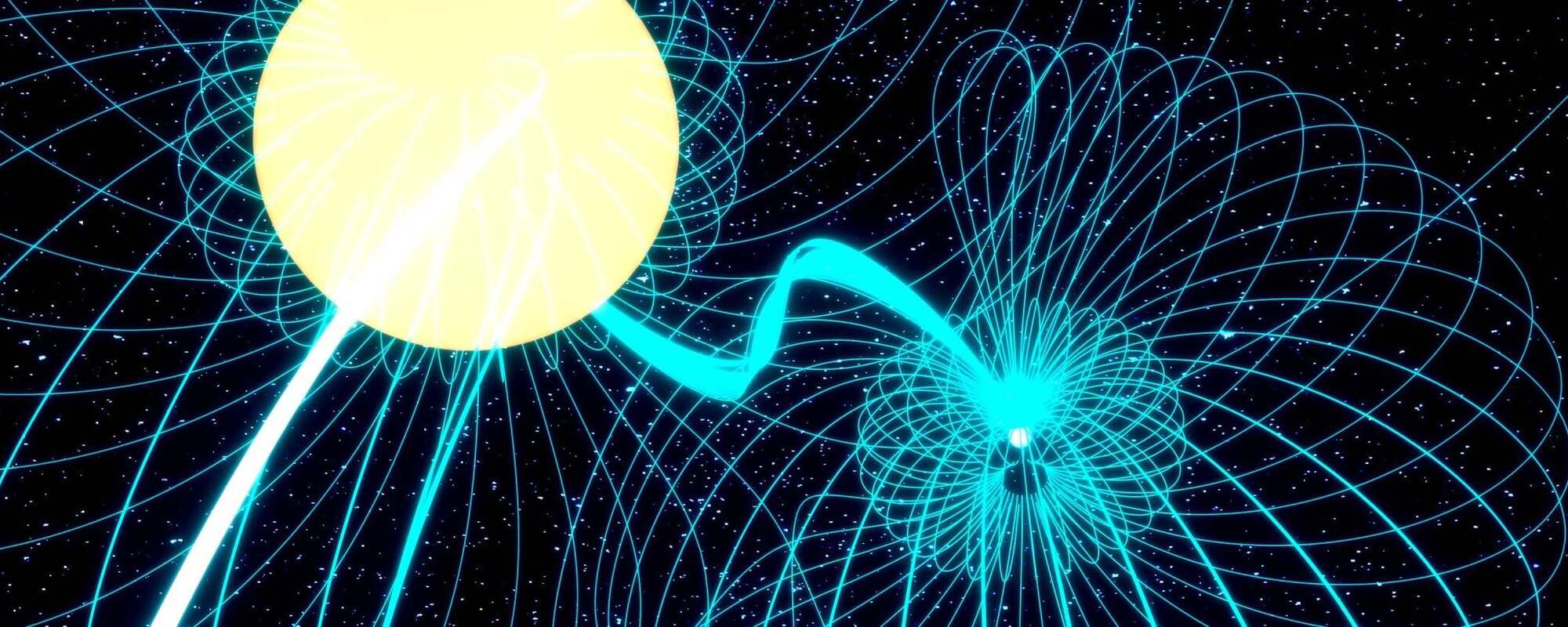
Within their planetary systems, stars are continuously shaping their orbiting planets through gravity, radiation and magnetic forces. So far, this relationship has appeared to be a one-way street.
But through new research published in Science, an international research team has found compelling evidence that the dynamic can run in reverse: A giant exoplanet orbiting very close to its star appears to be leaving a measurable magnetic imprint on the star itself.
The International Space Station is now home to an even more capable quantum laboratory, where NASA cools atoms to nearly absolute zero to study one of the strangest states of matter known.
James Webb uncovered exotic salt clouds surrounding the famous “Pink Planet,” solving a long-standing mystery about one of the coldest known alien worlds.
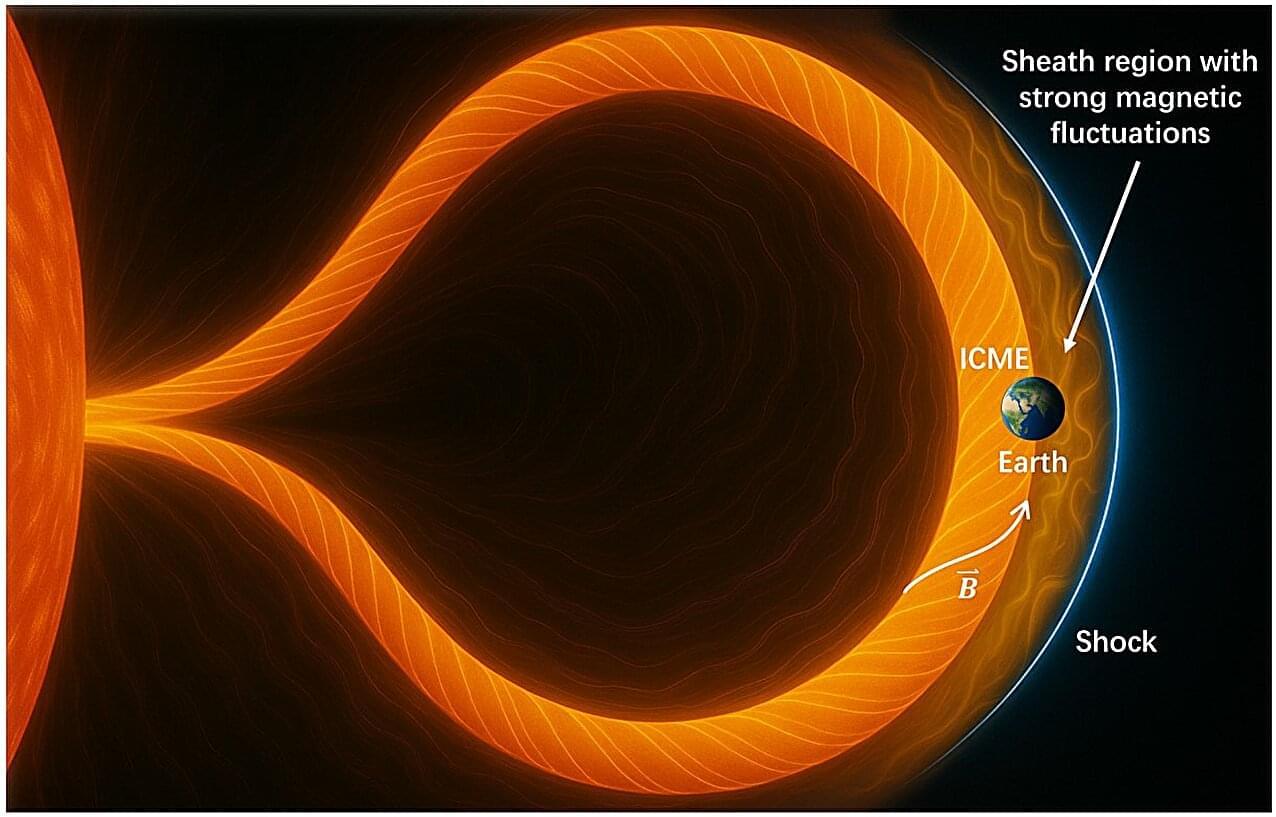
A new study has revealed an unexpected link between solar storms and the flux of high-energy cosmic rays arriving at Earth. The findings, made using one of the world’s largest cosmic ray detectors, could open up a new way to probe the magnetic structures inside solar storms—and potentially improve our ability to forecast their effects on Earth. The research has been published in Physical Review Letters.
Earth’s magnetic field is constantly being bombarded by energetic charged particles, originating from two very different sources. While some of these particles are cosmic rays, which come toward Earth from all directions across the galaxy, the rest originate from solar storms: violent outbursts from the sun that hurl vast clouds of magnetized plasma into space.
So far, the effects of these two phenomena have often been treated as independent. Although scientists have long known that solar storms can reduce the number of lower-energy cosmic rays reaching Earth by trapping them in the storm’s twisted magnetic fields, higher-energy cosmic rays were thought to be too energetic to be affected. At these energies, the particles were expected to punch straight through the magnetic structures without being deflected.
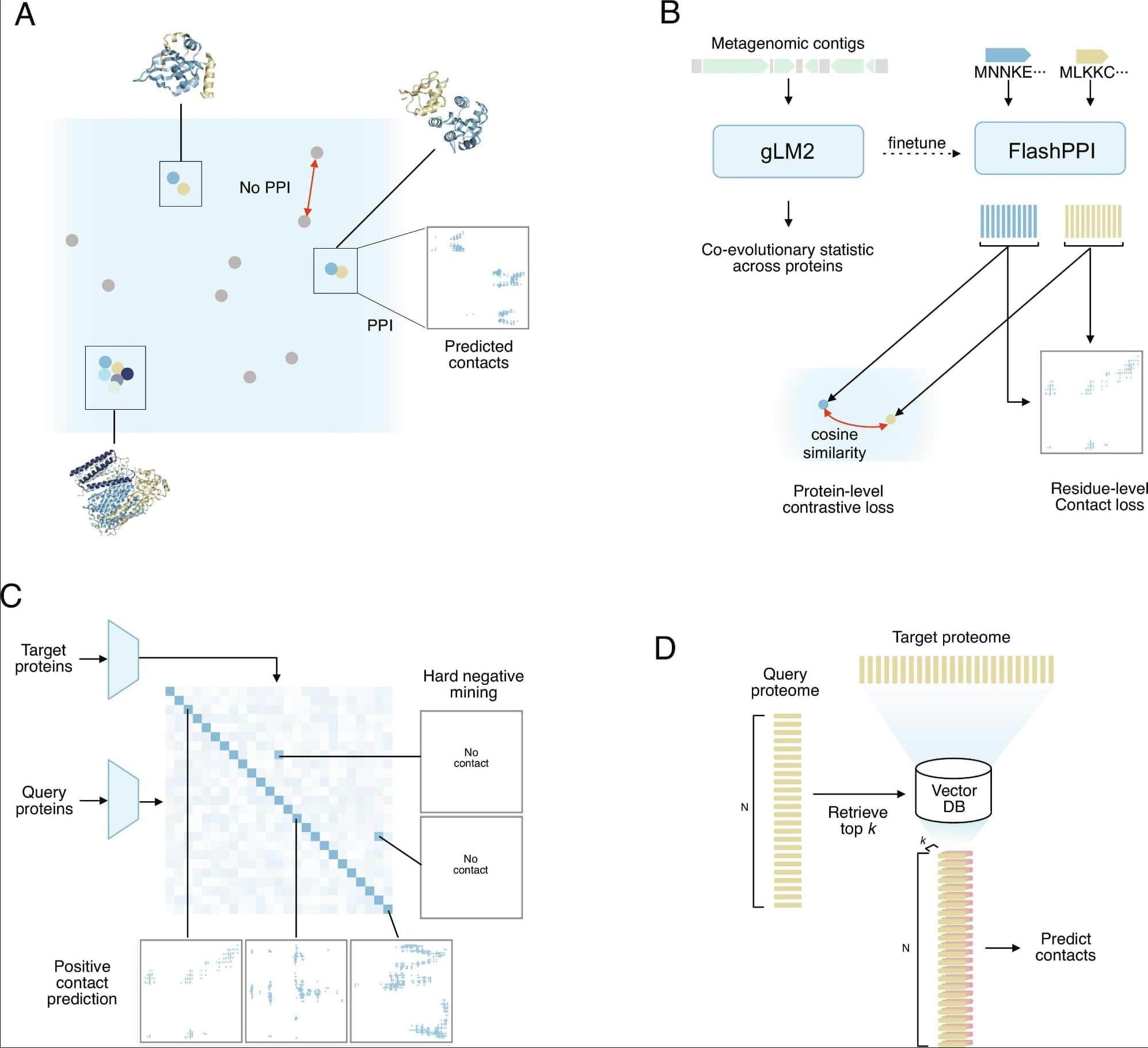
Protein–protein interactions (PPIs) underpin biological function, yet proteome-scale interaction prediction remains bottlenecked by the quadratic computational complexity of all-vs.-all pairwise comparisons. Here, we present FlashPPI, a contrastive learning framework, grounded in residue-level interactions, that enables linear-time prediction of physical protein interfaces across a microbial proteome. By leveraging a genomic language model that captures cross-protein coevolutionary signals from metagenomic sequences, FlashPPI aligns interacting partners in a shared latent space. We demonstrate a four-fold performance increase over existing sequence-based methods, while reducing proteome-wide screening time from days to minutes. Crucially, FlashPPI achieves comparable screening performance to state-of-the-art structure-folding models at a fraction of the computational cost. Finally, we integrate FlashPPI into an interactive web platform that combines predicted networks with functional annotations and genomic context, making proteome-wide network analysis rapid and accessible for microbial discovery.
From cosmic rays to solar storms, space travel is a radiation gauntlet… but water may be the simplest, smartest solution. Discover how future starships might turn their life-support systems into life-saving armor.
Get Nebula using my link for 50% off an annual subscription: https://go.nebula.tv/isaacarthur. Watch my exclusive video Nearby Supernovae: https://nebula.tv/videos/isaacarthur–… out Gods & Monsters: https://nebula.tv/curiousarchive/gods… 🛒 SFIA Merchandise: https://isaac-arthur-shop.fourthwall… 🌐 Visit our Website: http://www.isaacarthur.net ❤️ Support us on Patreon: / isaacarthur ⭐ Support us on Subscribestar: https://www.subscribestar.com/isaac-a… 👥 Facebook Group: / 1,583,992,725,237,264 📣 Reddit Community: / isaacarthur 🐦 Follow on Twitter / X: / isaac_a_arthur 💬 SFIA Discord Server: / discord Credits: Fishbowl Starships Water As Shielding Episode 721; June 1, 2025; Nebula Exclusive Written, Produced, & Narrated by: Isaac Arthur Graphics: Bryan Versteeg, Jeremy Jozwik, Udo Schroeter Select imagery/video supplied by Getty Images Music Courtesy of Epidemic Sound http://epidemicsound.com/creator Taras Harkavyi, “Alpha and…” Chris Zabriskie, “Unfoldment, Revealment”, “A New Day in a New Sector” “Oxygen Garden”, “Wonder Cycle” Stellardrone, “Red Giant”, “Billions and Billions” Chapters: 0:00 Intro 1:45 The Threat — Radiation In Space 2:36 Galactic Cosmic Rays (GCRs) 3:44 Solar Particle Events (SPEs) 4:16 Van Allen Belt Radiation 5:19 Radiation’s Impact on Humans and Equipment 8:18 Radiation Shielding Basics 9:18 Water as a Radiation Shield 11:19 Effectiveness of Water 15:42 Difficulties Using Water 17:29 Beyond Water: Alternative Radiation Shielding Methods 17:59 Metallic Shielding 18:58 Regolith & Asteroid-Based Shielding 20:27 Hydrogen-Rich Polymers 21:22 Graphene, CNTs, and BNNTs 23:54 Active Shielding: Magnetic & Plasma Barriers 24:49 Fusion Fuel Shielding 25:27 Hybrid Shielding Approaches 28:16 God & Monsters 29:26 The Future of Radiation Shielding 30:00 Smart & Self-Healing Shielding 31:29 Artificial Magnetospheres 33:22 Biological Adaptation 35:35 Radiation-Resistant AI & Robotics 37:45 The Future of Space Radiation Protection 38:55 The Future of Water-Based Shielding. Check out Gods \& Monsters: https://nebula.tv/curiousarchive/gods…
🛒 SFIA Merchandise: https://isaac-arthur-shop.fourthwall… 🌐 Visit our Website: http://www.isaacarthur.net. ❤️ Support us on Patreon: / isaacarthur. ⭐ Support us on Subscribestar: https://www.subscribestar.com/isaac-a… 👥 Facebook Group: / 1583992725237264 📣 Reddit Community: / isaacarthur. 🐦 Follow on Twitter / X: / isaac_a_arthur. 💬 SFIA Discord Server: / discord. Credits: Fishbowl Starships Water As Shielding. Episode 721; June 1, 2025; Nebula Exclusive. Written, Produced, \& Narrated by: Isaac Arthur. Graphics: Bryan Versteeg, Jeremy Jozwik, Udo Schroeter. Select imagery/video supplied by Getty Images. Music Courtesy of Epidemic Sound http://epidemicsound.com/creator. Taras Harkavyi, \
Fourteen years ago, Cory Doctorow told me the #Singularity is a progressive apocalypse.
I have not stopped thinking about that phrase since.
We like to imagine the future as one clean break. A line crossed. A god booted up in a server farm. Cory saw something stranger. The end of the world, sold to us as the perfection of the world. Rapture for the people who swapped faith for code.
His sharpest point was about stories. Good #ScienceFiction does not predict the future. It predicts the present. The genre is not a telescope. It is a mirror.
Re-listening in 2026, the reflection is uncomfortable.
The surveillance he warned about is now infrastructure. The platforms he distrusted now mediate almost everything we do. We still treat the internet as a glorified video-on-demand service, and we still pour everything we are onto it anyway.
To build a Proxima Centauri b generational ship; designed to protect the life aboard during the 100 year journey from Earth; designed to build the first structures of the settlement on the surface of the new planet.
✧ Find me on Substack where I write sci-fi story essays: J.Barry / Between Worlds. https://jbarrybetweenworlds.substack… The fourth volume of ‘The Encyclopedia of the Future’ is now available on my Patreon. / shop ✧ The Garden Telescope (and Other Short Stories) Ebook is also available to Patreon members, or as a single purchase download Visit my Patreon here: / venturecity Created by: J. Barry — Book recommendations on artificial intelligence, future technology and innovations, and sci-fi stories (affiliate links): • Superintelligence: Paths, Dangers, Strategies https://amzn.to/3j28WkP • Life 3.0: Being Human in the Age of Artificial Intelligence https://amzn.to/3790bU1 • The Expanse: https://amzn.to/3Q0mG61 • The Hitchhikers Guide to the Galaxy: https://amzn.to/3kNFSyW — Other videos to watch: 1. The 100 Year Journey to Proxima Centauri b • The 100 Year Journey to Proxima Centauri B… 2. The First 10,000 Days on Proxima Centauri b • The First 10,000 Days on Proxima Centauri… 3. TIMELAPSE of Future Space Stations • TIMELAPSE of Future Space Stations. ✧ The fourth volume of ‘The Encyclopedia of the Future’ is now available on my Patreon. / shop. ✧ The Garden Telescope (and Other Short Stories) Ebook is also available to Patreon members, or as a single purchase download.
Visit my Patreon here: / venturecity.
Created by: J. Barry.
Book recommendations on artificial intelligence, future technology and innovations, and sci-fi stories (affiliate links): • Superintelligence: Paths, Dangers, Strategies https://amzn.to/3j28WkP • Life 3.0: Being Human in the Age of Artificial Intelligence https://amzn.to/3790bU1 • The Expanse: https://amzn.to/3Q0mG61 • The Hitchhikers Guide to the Galaxy: https://amzn.to/3kNFSyW
A solar storm hitting Earth appears to have reduced the amount of incoming high-energy cosmic rays, suggesting a new way of measuring solar activity.
Solar activity has a well-known impact on the flux of low-energy cosmic rays that strike Earth. Now researchers have detected a solar-storm-induced change in the flux of higher-energy cosmic rays [1]. Using data from a large detector array in China, the team measured a decrease—over several hours—in cosmic-ray showers coming from a particular direction in the sky. The timing of this anisotropy suggests that cosmic rays heading into the outward-moving storm were preferentially scattered by the storm’s magnetic fields. The results could lead to a new way to study the magnetic structures in solar storms.
The solar wind—the spray of charged particles continually emitted by the Sun—partially shields Earth and other planets from cosmic rays that stream into the Solar System from all directions. The wind contains magnetic fields that help deflect the high-energy protons and other particles that make up the cosmic rays. In 2024, when the wind was at the peak in its 11-year cycle, the flux of cosmic rays was down by about 0.5% compared to the average.