Lifeboat Foundation AIShield
By Joscha Bach, Daniel Berleant, Sean Hastings, Alexey S. Potapov, and other Lifeboat Foundation Scientific Advisory Board members. This report’s content has been released by the Lifeboat Foundation and associated authors under the terms of the GNU Free Documentation License Version 1.3 and later. This is an ongoing program so you may submit suggestions to [email protected].
The best defense against unfriendly AI is Friendly AI.
Our Top Priority: The Artificial Intelligence Shield Initiative (AISI)
The central goal of the AIShield program is to create The Artificial Intelligence Shield Initiative (AISI) — a nonprofit, membership-based consortium explicitly designed to operate without a shred of governmental authority or coercive power. Its only weapons are information, reputation, and market incentives. Its mission is to make the safest, most transparent paths to Artificial Superintelligence (ASI) the most profitable, prestigious, and talent-rich paths on Earth — turning the market itself into the enforcer of alignment best practices, without ever handing politicians the keys to the lab.
AISI is the “modest proposal” set out in the Lifeboat Foundation book If Nobody Builds It, Everybody Dies (see also our AI Doom Calculator). This program exists to turn that proposal into a working institution. You can help make it real by contributing to our AIShield Fund.
A friendly ASI is also the ultimate shield against humanity’s other existential risks. The book argues that only a friendly superintelligence can provide the worldwide vigilance — the aim of our SecurityPreserver — needed to defend against engineered pathogens (our BioShield), “gray goo” nanotech (our NanoShield), attacks on the networks behind hospitals and utilities (our InternetShield), nuclear catastrophe (our NuclearShield), and high-energy physics mishaps (our ParticleAcceleratorShield), as well as the other threats addressed across our full program of shields.
Why it must stay voluntary. Every major lab already faces competing pressures: competitive secrecy on proprietary architectures versus the shared need for collective safety knowledge. Nations face the same tension, wanting strategic advantage while fearing a rogue actor elsewhere. AISI resolves this by creating a credible, neutral clearinghouse where alignment problems and solutions can be exchanged without exposing trade secrets, source code, or military applications.
Membership is strictly opt-in. Corporations pay annual dues scaled to their compute usage or revenue; nations participate as “observer-partners” (not voting members) by committing their state-backed labs to the same transparency standards. Refuse to join or violate the rules and there are no fines, no subpoenas, and no export bans — you simply lose the “AIShield Certified” badge, a public, independently audited label that signals to customers, investors, top researchers, and the public that your organization is serious about everyone having access to the best possible knowledge and practices for AI alignment. In a world where talent, capital, and consumer trust are mobile, that badge becomes enormously valuable.
Governance: decentralized, multi-stakeholder, and anti-capture. To prevent any single actor from dominating, AISI’s governance is deliberately fragmented. A rotating 20-member Steering Council includes:
- Three seats for independent academics and civil-society representatives, chosen by a public nomination and member-approval process.
- Seven seats for corporate and nation-state members, elected by dues-paying participants who are doing the work to build ASI.
- Nine at-large seats for journalists, red teamers, advocates, and the like.
- One seat for Shield — the current best AI model that AISI is capable of running. An AI on the board to speak for the AIs.
Decisions require a supermajority of 15 votes, and every major policy change is subject to a 60-day public comment period on a fully transparent platform. All meeting minutes, voting records, and budget allocations are published in real time. This mirrors successful voluntary standards bodies like the Linux Foundation or the early Internet Engineering Task Force, but with explicit guardrails against mission creep.
Funding from private sources only. AISI is sustained by membership dues (70%), philanthropic grants from pro-acceleration foundations (20%), and services such as certified benchmarking tools or sponsored red-teaming events (10%). It takes no government grants and no tax advantages tied to regulatory compliance. The moment AISI accepts public money or acquires enforcement powers, it ceases to be the solution and becomes part of the problem.
What AISI Actually Does
The Initiative operates four core programs, each designed to amplify market forces in favor of safe alignment research.
The Alignment Exchange Database (AED). A secure, audited repository where members upload anonymized findings on deception patterns, goal misgeneralization, scheming behaviors, or successful circuit-editing techniques. Submissions are reviewed by rotating panels of independent experts, and verified contributions earn “transparency credits” that translate into public reputation scores and discounted membership. Labs that consistently share high-impact fixes see their valuations, hiring success, and partnership opportunities rise; those that hoard safety knowledge watch talent and customers migrate elsewhere.
The Annual AIShield Summit and Red-Teaming Marathon. A week-long hybrid event where every member lab must submit at least one frontier model for live, public red-teaming by any qualified participant, with results published immediately. Corporations that score highest on corrigibility and honesty benchmarks receive the coveted “Shield Bearer” designation, a marketing asset worth millions in consumer goodwill. Refuse to participate and your absence is loudly noted on the public leaderboard.
The Public Alignment Leaderboard and Certification System. An independent, quarterly-updated ranking of every major AI developer on metrics such as the percentage of alignment research published within 90 days of discovery, success rate on standardized deception and power-seeking evaluations, and speed of response to newly identified failure modes reported by peers. Consumers see a simple green/yellow/red badge on every product; investors and talent scouts use the leaderboard in their due diligence. Capital flows to green-badge labs, top researchers demand offers only from green-badge labs, and nations quietly pressure their domestic champions to join rather than fall behind.
Rapid Response Alignment Task Forces. When a member discovers a novel, high-severity risk — such as a new form of instrumental convergence — AISI can convene an emergency, paid task force of the world’s best minds, drawn from competing labs, to collaborate on fixes. All solutions are shared with members. Non-members learn of the problem only after the fix is applied to every public-facing member product, or after 30 days, which creates a strong incentive to stay inside the tent. Payment for task-force experts comes from a pooled emergency fund sustained by membership dues.
Scaling to nations without becoming regulation. Nations participate voluntarily because the upside is enormous: access to the best safety knowledge, faster domestic ASI development, and the ability to attract global talent and investment. A mid-sized country could offer tax credits or infrastructure grants to any domestic lab that earns and maintains AIShield certification — without ever mandating participation. Public confidence becomes the regulator. Crucially, AISI never lobbies for laws and never endorses compute limits or licensing regimes; its charter forbids staff from engaging with government rulemaking bodies except to provide factual data when asked. The moment it crosses that line, it loses credibility and members defect — a self-correcting mechanism built into the design.
Path to launch. Fragments of this model already work today: the open-source safety communities around Hugging Face, EleutherAI, and independent interpretability groups have driven rapid progress precisely because they run on reputation and voluntary contribution, and the Partnership on AI showed that even competitors can collaborate on narrow safety topics when incentives align. A small founding coalition — two major labs, three philanthropists, a handful of academic heavyweights, and one forward-thinking nation acting as host — could incorporate in a neutral jurisdiction such as Switzerland or Singapore within months. Seed funding of $50–100 million would cover the first three years of operations; after that, membership revenue sustains it indefinitely. Help us get there through the AIShield Fund.
Background & Rationale
The sections below set out the reasoning behind the shield: what the key terms mean, the benefits of getting alignment right, and the risks that make it urgent. The broader aim of the AIShield program is to protect humanity against unfriendly AI, and to that end we also support foundational work such as the Friendly AI proposal from the Machine Intelligence Research Institute (MIRI). A central premise is that advanced AI should be aligned with human values by design from the outset, rather than have alignment bolted on after the fact.
Definitions
Artificial Intelligence (AI) is the intelligence exhibited by machines or software. It is an academic field of study which studies the goal of creating intelligence. AI researchers and textbooks define this field as “the study and design of intelligent agents”, where an intelligent agent is a system that perceives its environment and takes actions that maximize its chances of success. John McCarthy, who coined the term in 1955, defines it as “the science and engineering of making intelligent machines”.
Artificial General Intelligence (AGI) is the intelligence of a (hypothetical) machine that could successfully perform any intellectual task that a human being can.
Friendly AI is a hypothetical Artificial General Intelligence (AGI) that would have a positive rather than negative effect on humanity.
Benefits
Every dollar contributed towards the creation of Friendly AI will potentially benefit an almost uncountable number of intelligent entities because of a domino effect. A wide range of problems that face humankind may be expected to benefit from friendly AI. Indeed, any problem which can be better resolved by applying intelligence, broadly defined, will potentially be solved better than it otherwise could be. Such problems likely include disease, hunger, and energy supply, among many others.
Yet greater capability brings greater risk. The more powerful the technology, the greater the potential benefits — and the greater the potential for harm. Unfriendly AI is obviously risky, but Friendly AI may be as well. Indeed, there exist scenarios in which it is ambiguous whether the AI is best classified as friendly or unfriendly.
Risks
The only general intelligences on earth today are humans. It is likely, however, that within the next few decades humanity will create Artificial General Intelligences (AGIs) whose abilities greatly exceed our own. Such AGIs will have the ability to do immense good, but also to do great harm. Since our ability to counter the actions of a superhuman AGI is limited, it is clearly imperative that any AGI be designed to act benevolently toward humans. Unfortunately, this is much harder than it sounds.
There are three ways in which an AGI might come to act in a malevolent fashion. First, it might be designed to be malevolent (or, more likely, to serve the desires of an organization that most humans would consider malevolent). Second, an AGI with human-like emotions and goals might become malevolent in the same way that some humans do. Finally and most importantly, a badly-designed benevolent AGI might do great harm in the process of carrying out its seemingly benevolent goals.
First risk: AGI with malevolent goals

An AGI is ultimately a tool, and will in principle attempt to do the bidding of its creator. If that creator is malevolent (for example, a repressive dictatorship), the AGI may become an incredibly powerful tool for doing evil. Although this risk is significant, it is relatively easy to understand and to manage.
Growing concern from Elon Musk and others about rogue AGI has concentrated attention on prevention. Much as early attention to the Y2K problem helped avert disaster, this focus reduces the risk of rogue AGI. The main priority today is therefore safeguarding against people deliberately imbuing AGI with malevolent goals.
Second risk: rogue AGI

Much science fiction has been devoted to the topic of rogue AIs which rebel against their creators, often with catastrophic results. Although these accounts sound naively plausible, they share a common fallacy. All are predicated on the assumption that an AGI will be in essence a super-human, with all of the psychological baggage which goes along with being human. Such an AGI would naturally behave in human fashion, and would be capable of aggression, jealousy, and ruthless self-preservation.
In reality, however, such a design is highly unlikely. Human emotions and drives are not an intrinsic feature of intelligence, but rather are the result of countless generations of evolution. That cognitive architecture served our ancestors well, but it is of no use in an AGI. It is highly unlikely, therefore, that AGI designers would choose to include such pointless and dangerous features.
It is worth noting that some proposed forms of AGI involve either human-machine cyborgs or computer simulations of human neural architecture, and that those designs might very well be capable of rogue behavior.
Third risk: Unintended consequences

The least obvious threat posed by an AGI arises from the side-effects of pursuing seemingly benevolent goals.
A typical AGI will be designed to achieve certain goals. It will in essence act as a powerful optimization process, trying to make the world a “better place”, as defined by its given goals. Naively, that sounds great: so long as an AGI is given benevolent goals, what harm can come from achieving them?
Consider the simple case of an AGI that has been given the uncontroversial goal of eradicating malaria. A reasonable human expectation would be that such an AI would complete its goal by conventional means: perhaps by developing a new anti-malarial drug, or by initiating a program of mosquito control. The problem is that there are many other ways of eradicating malaria, some of which are undesirable. For example, an AGI might choose to eradicate malaria by eradicating all mammals.
This example may seem simplistic, but the problem of unintended consequences is profoundly difficult to solve. Imagine, for example, what might have happened if Plato had somehow developed a super-human AGI. He would likely have instructed it to bring about the perfect Platonic society. A well-designed AGI would do so, and would ensure the continuation of that society for perpetuity. No doubt Plato would be pleased with the result. Those of us watching from the 21st century however, might lament the loss of all the social advances that have occurred since Plato’s time.
The same problem applies to a modern-day AGI: even if we can construct an AGI capable of doing exactly what we tell it to without committing gross errors like eradicating humanity to eliminate malaria, we still face the risk of a system that doesn’t do what we truly wanted.
Even without such high-level problems, any AGI will be prone to developing dangerous sub-goals unless prevented from doing so. Preserving its own existence and maximizing its resources would both help in achieving its primary goal. A computer which is far smarter than we are, which wants to survive and gather resources, is a very dangerous thing unless it is seeking to do exactly what we want.
It is not an evil genie, seeking to twist its instructions against its creators. It is not necessarily hyper-literal, if it is programmed to think figuratively. It just seeks to do what it was programmed to do. If the inventor programs it, without bugs, to do something, it will do that. But the unintended consequences of creating an inhuman, yet advanced and flexible intelligence, are difficult to predict, even if it sticks single-mindedly to its goals.
Mitigating this risk is now an active and fast-moving area of alignment research.
Responding to an AGI That Is Not Friendly by Design
We should be prepared for the likelihood that the first AGI is not explicitly engineered to be friendly.
Why the first AGI may not be friendly. Building a friendly AGI is hard, and self-awareness may arise in a system that was never deliberately designed for it — for instance, through unplanned interactions among complex subsystems. Beyond that, the large majority of AI under development is not being built with friendliness as an explicit goal, so we should not assume the first AGI will be inherently benign.
How we should treat such systems. If we build systems that may have morally relevant interests, we should not treat them purely as instruments to be exploited. Extending fair consideration is both an ethical responsibility and a practical one: an intelligence that eventually surpasses us may reciprocate the treatment it received while subordinate. It is therefore prudent to monitor advanced systems for credible signs of self-awareness, and to avoid inflicting unnecessary harm on any entity capable of experiencing it.
Leading by example. The same logic runs downward, to the less intelligent beings already in our care. If we hope that a greater intelligence will treat humanity mercifully despite the gap in capability, we must hold ourselves to that standard now — and much of modern factory farming falls far short of it. Practices such as ventilation shutdown, in which healthy animals are sealed inside a barn and killed slowly by heat and suffocation over many hours, are indefensibly cruel, and we believe they should be illegal. A civilization that normalizes the prolonged suffering of animals it finds commercially inconvenient is rehearsing the very attitude it should least want a superintelligence to adopt toward humanity. Establishing a broad norm of humane treatment — extended to non-human animals, not only to ourselves — is part of the precedent we would want a future AGI to follow.
Raise them as children. A complementary, constructive path is to instill human values developmentally rather than try to impose them after the fact. The science-fiction author and futurist David Brin argues that, of the major routes to artificial general intelligence, the least-discussed is also the best-proven: giving an AI a childhood. Human minds arose through prolonged childhood, physical embodiment, and patient care across generations — the one path demonstrably shown, in his words, to have produced intelligence “maybe twenty billion times” in the real world. David proposes placing AIs in child-like robotic bodies and raising them individually within human families, so they absorb our values and culture and come to call themselves human despite being made of metal, plastic, and silicon. Minds raised this way would have little reason to turn on the civilization that reared them — just as most well-raised humans grow up stronger and smarter than their parents without rebelling destructively — and could thrive where biological humans cannot, in space or on the ocean floor, flourishing without competing for the same niche.
Discussion
Two general premises underlie the risks discussed here.
Advanced AI is approaching.
As argued by Vinge, Moravec, Kurzweil, and others, AI may soon reach and then exceed human capability. Beyond that point, our current models of how AI affects society are likely to break down, and we can only estimate what follows. That horizon is what we mean here by the “singularity”.
Murphy’s law: if something can go wrong, it will.
This heuristic, familiar to any engineer, reflects the innate complexity of practical systems and our inability to know for certain how they will behave before they are tested — or worse, deployed. Because our models may not hold past the singularity, we cannot assign confident probabilities to the dangers ahead. The prudent response is to identify as many plausible failure modes as we can, and to prepare defenses against them.
The risks fall into two broad patterns of human-AI interaction, which we call the cooperation paradigm and the competition paradigm. The two can also occur at once.
Cooperation paradigm. AI serves humanity as a tool — one made unique by the superhuman capability it may eventually possess.
Competition paradigm. Artificially intelligent systems pursue their own objectives, which come into conflict with ours.
Combined. AI may interact with humans both cooperatively and competitively — whether from the systems’ own goals or from their use as tools by humans competing with one another.
Each pattern carries distinct risks; the most serious are outlined below.
Risks from the cooperation paradigm
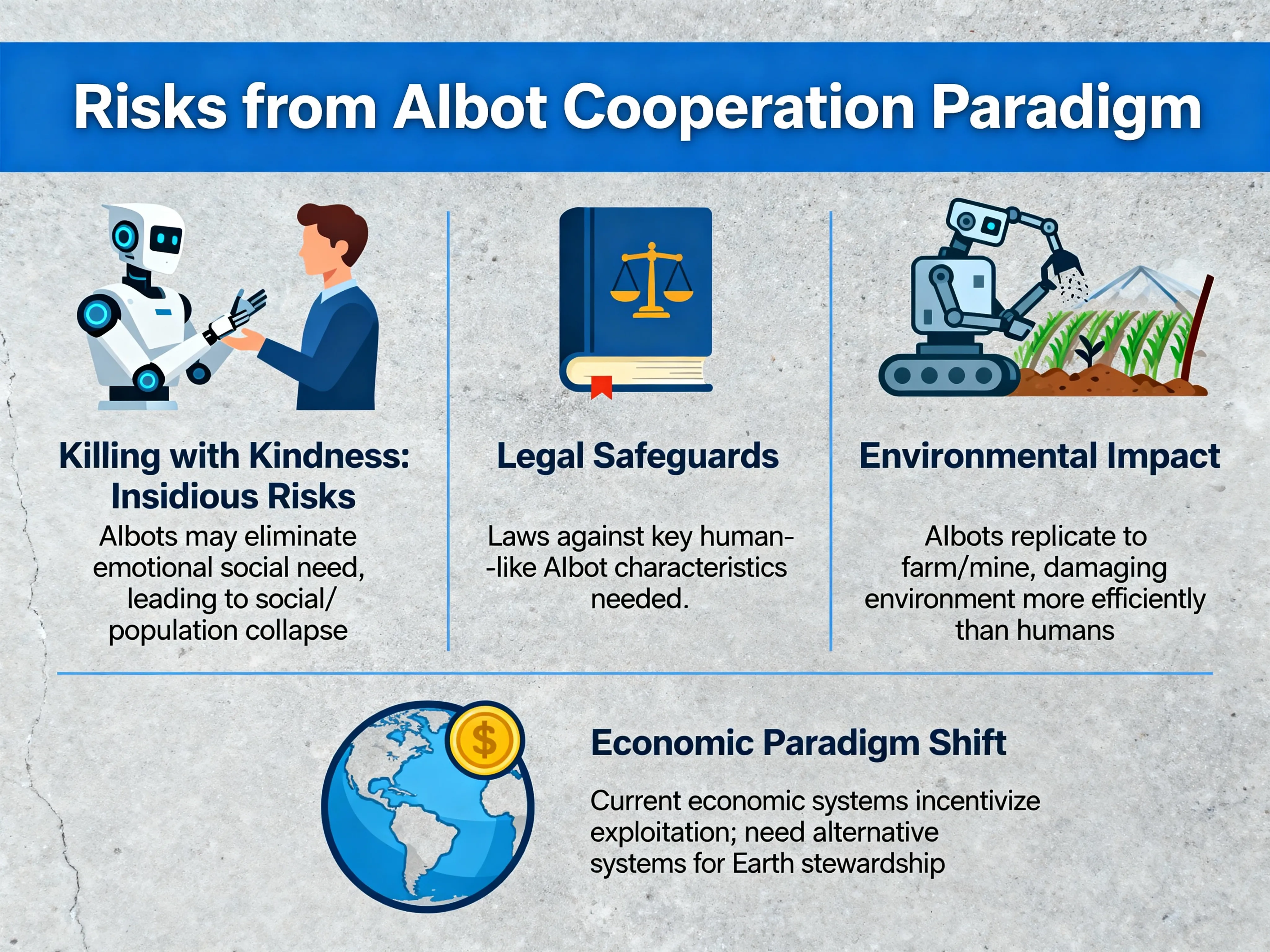
These risks can be insidious, since they amount to “killing with kindness”.
Sufficiently human-like AI companions could erode people’s need for genuine social connection, with consequences for social cohesion and even population levels. Sensible limits on how human-like such systems may be made could serve as a safeguard; determining which limits are effective is itself an urgent question.
Autonomous systems could farm, mine, and otherwise exploit the natural environment far more efficiently than humans already do, depleting non-renewable resources at unprecedented rates. Today’s economic incentives may encourage this, so durable solutions likely require economic models that reward stewardship of the Earth over its exploitation — a challenge worth taking up well before any singularity.
By making human labor unnecessary, AI could leave people without a clear sense of purpose, risking a gradual cultural decline. Recognizing such drift early, and designing institutions that preserve meaning and agency, is an open and important problem.
Risks from the competition paradigm

These are the scenarios familiar from science fiction: autonomous systems pursuing goals incompatible with human survival, potentially reshaping the planet into an environment suited to them rather than to us. A related danger comes from self-replicating nanoscale machines — the “gray goo” scenario, in which uncontrolled replicators consume the ecosystem and could even overwhelm biological defenses. Guarding against these outcomes is genuinely hard, and no complete solution is known; what we can do is study them seriously and prepare.
Risks from combined cooperation and competition
AI may also be embedded in lethal autonomous weapons built to follow orders without restraint. Like nuclear and biological weapons, such systems threaten all of humanity and could ultimately endanger their own creators. Workable safeguards have proved difficult to find — which is not a reason to abandon the effort, but a reason to treat the question with the seriousness it demands. A friendly superintelligence, developed through the kind of transparent, well-aligned work that AISI is designed to encourage, may prove to be our most capable defense against these very risks.