The standard approach to satellite imagery is to snap huge batches of pictures and beam them back to Earth, where they can be sifted through by human operators and the best available algorithms.
It’s all worked well so far, but the time, transmission bandwidth, and energy required are starting to become bottlenecks. Modern satellites are simply capturing more pixels than scientists have time to look at.
However, the YAM-9 satellite has just done something different: It has identified and described features in its image scans without needing to check back with ground control.
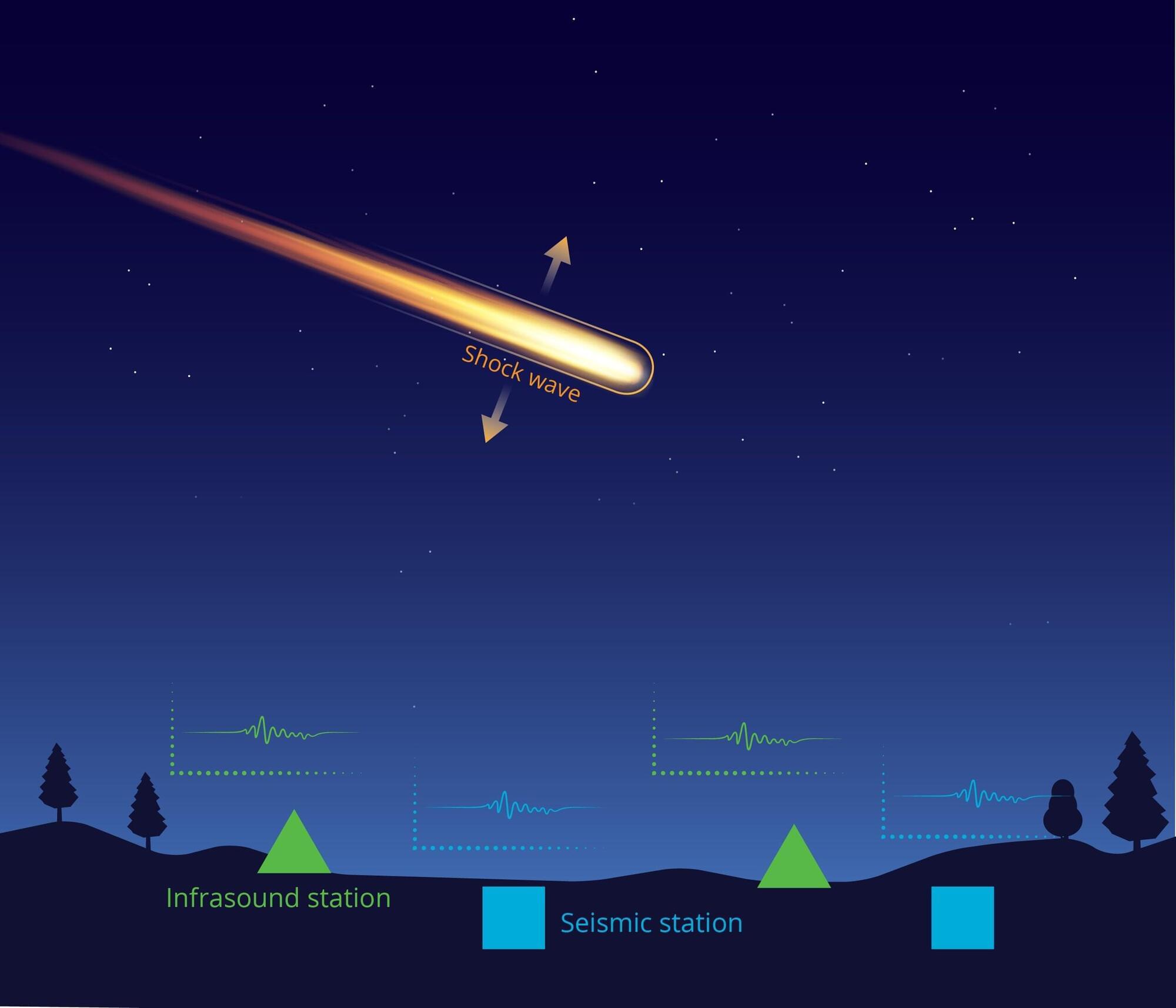
When a bright fireball streaked across the Alaska sky last spring, the usual tools scientists rely on to track such events—cameras and satellites—did not provide a detailed picture. But the meteoroid left behind something else: low-frequency sound waves that traveled hundreds of miles and were captured by a dense network of earthquake and volcano-monitoring sensors on the ground.
Using those signals, a Sandia National Laboratories-led team of researchers, students and citizen scientists reconstructed the object’s path through the atmosphere, where it broke apart and where debris likely fell.
In a study published in the Journal of Geophysical Research: Planets, the team showed how low-frequency sound waves, faint ground vibrations, weather radar data and publicly shared videos can be combined to reconstruct a fireball’s path even when optical coverage is sparse or incomplete.
TAMPA, Fla. — Five-month-old startup Orbital has asked the Federal Communications Commission for permission to deploy up to 100,000 data center satellites, aiming to bring 10 gigawatts of computing power from space to meet rising artificial intelligence demand.
The filings submitted June 24 add a few more details for a constellation the Los Angeles-based venture first outlined earlier this month, when it emerged from stealth with $5 million in pre-seed funding ahead of a demonstration mission next year.
They include plans to deploy 100-kilowatt-class satellites in low Earth orbit at altitudes of 500–850 kilometers, with solar arrays and radiators spanning around 100 meters and a dry mass of 1.5−2.5 metric tons.
But there is a vast difference between launching satellites and operating an industrial-scale computing infrastructure in orbit. Space is unforgiving. Radiation damages electronics. The electronics generate enormous amounts of heat, and getting rid of that heat is surprisingly difficult in space. Repairs are extraordinarily expensive, and every pound launched into orbit still carries a significant cost.
First off, consider what goes into an Earth-based data center, like those that you’ve probably begun to see pop up everywhere. These facilities power cloud computing, video streaming, online banking, scientific computing, and increasingly, artificial intelligence. But a data center is much more than a room full of servers.
WASHINGTON — Rocket Lab is acquiring satellite telecommunications company Iridium for $8 billion as part of its effort to become an end-to-end space company.
The companies announced an agreement June 29 under which Rocket Lab will acquire Iridium for $54 a share in cash and stock, valuing Iridium at $8 billion. That is a 24% premium over the closing price of Iridium’s shares June 26. The deal is projected to close in mid-2027 pending regulatory and other approvals.
Mesh Optical came out of stealth in February when it announced that it raised a $50 million Series A led by Thrive Capital.
Before founding Mesh Optical, the startup’s co-founders, Travis Brashears, Cameron Ramos, and Serena Grown-Haeberli, developed the optical communication links that keep thousands of SpaceX’s Starlink satellites interconnected.
The Mesh co-founders saw an opportunity to develop optical transceivers for terrestrial data centers, as light-based hardware is faster and more energy-efficient than traditional electrical-based systems.
TAMPA, Fla. — British startup Shield Space plans to combine its autonomous satellite operations software with ClearSpace’s in-orbit servicing capabilities to address emerging orbital threats.
The startup signed a memorandum of understanding June 23 with ClearSpace’s British subsidiary to develop sovereign space defense capabilities for the United Kingdom and its allies, which they say are increasingly important as adversaries step up efforts to monitor, disrupt and potentially disable critical satellite infrastructure.
Founded in 2025, Shield Space is developing software designed to keep satellites operating autonomously even when communications with the ground are disrupted.
Get a great Displate deal using my link https://displate.com/l/marcushouse or my discount code MARCUSHOUSE. 1 Displate — 22% off. 2 Displates — 27% off. 3+ Displates — 33% off. Not valid on Limited Edition.
SpaceX may have just dropped its biggest hint yet about what comes after Starship Flight 13. Indeed, FINALLY! Starship’s Next Giant Leap may be here as the new filings point toward an Orbital Return Demo that could mark the next major milestone on the road to full reusability. With that work continues at Starbase on Pads 1 and 2, the Gigabay, and future launch infrastructure. Elsewhere this week, we cover Falcon 9 launches carrying BlueBird satellites, Starlink, and another classified NRO mission, Cargo Dragon’s return from the International Space Station, Astrobotic’s Griffin lunar lander preparing for launch, Ariane 6’s impressive upgraded debut with its heaviest payload yet, and the dramatic demolition of historic structures at Space Launch Complex 6.





{kind=link}