Category: robotics/AI – Page 41
Daniel Dennett: Philosophy, Robert Sapolsky, Human Clones, Free Will, Existence
The deepest dive into philosopher Daniel Dennett’s mind.
TIMESTAMPS:
00:00 — The Soul.
03:18 — Most Important Philosophical Question.
12:06 — Do Qualia Exist?
30:28 — Uploading Consciousness.
39:55 — Thinking Differently.
56:20 — Pragmatism.
1:01:06 — Robert Sapolsky.
1:12:57 — Philosophers and Scientists.
1:29:30 — Patterns and Emergence.
1:36:46 — Roger Penrose.
1:42:39 — Sailing Boats.
1:45:40 — Fictionalism.
1:51:12 — Coming Up With Concepts.
1:59:55 — Douglas Hofstadter.
2:05:30 — AI Alignment Problem.
2:11:31 — Q&A
NOTE: The perspectives expressed by guests don’t necessarily mirror my own. There’s a versicolored arrangement of people on TOE, each harboring distinct viewpoints, as part of my endeavor to understand the perspectives that exist.
THANK YOU: To Mike Duffey for your insight, help, and recommendations on this channel.
Support TOE:
- Patreon: https://patreon.com/curtjaimungal (early access to ad-free audio episodes!)
- Crypto: https://tinyurl.com/cryptoTOE
- PayPal: https://tinyurl.com/paypalTOE
- TOE Merch: https://tinyurl.com/TOEmerch.
Follow TOE:

Teaching robots to map large environments
A robot searching for workers trapped in a partially collapsed mine shaft must rapidly generate a map of the scene and identify its location within that scene as it navigates the treacherous terrain.
Researchers have recently started building powerful machine-learning models to perform this complex task using only images from the robot’s onboard cameras, but even the best models can only process a few images at a time. In a real-world disaster where every second counts, a search-and-rescue robot would need to quickly traverse large areas and process thousands of images to complete its mission.
To overcome this problem, MIT researchers drew on ideas from both recent artificial intelligence vision models and classical computer vision to develop a new system that can process an arbitrary number of images. Their system accurately generates 3D maps of complicated scenes like a crowded office corridor in a matter of seconds.

Robots That Feel Pain: Scientists Develop Human-Like Artificial Skin With Instant Reflexes
This technology is quite different from the workings of most robots used today. Many robots lack the ability to sense touch at all, and those that do can usually only detect simple pressure. Such robots lack self-protective reflexes.
In these systems, touch information first travels to the software, where it is analysed step-by-step before a response is determined. This process might be acceptable for robots working within safety enclosures in factories, but it’s insufficient for humanoid robots working in close proximity to humans.
Unlike humans, robots cannot heal themselves. However, scientists say the best alternative is quick and easy repair. According to them, the new skin converts touch signals into neural-like pulses and activates protective reflexes upon detecting pain. The skin can also detect damage, and thanks to its modular design, damaged sections can be quickly replaced.
The data center boom in the desert
The AI race is transforming northwestern Nevada into one of the world’s largest data-center markets—and sparking fears of water strains in the nation’s driest state.
CRISPR vs Aging: What’s Actually Happening Right Now
🧠 VIDEO SUMMARY:
CRISPR gene editing in 2025 is no longer science fiction. From curing rare immune disorders and type 1 diabetes to lowering cholesterol and reversing blindness in mice, breakthroughs are transforming medicine today. With AI accelerating precision tools like base editing and prime editing, CRISPR not only cures diseases but also promises longer, healthier lives and maybe even longevity escape velocity.
0:00 – INTRO — First human treated with prime editing.
0:35 — The DNA Problem.
1:44 – CRISPR 1.0 — The Breakthrough.
3:19 – AI + CRISPR 2.0 & 3.0
4:47 – Epigenetic Reprogramming.
5:54 – From the Lab to the Body.
7:28 – Risks, Ethics & Power.
8:59 – The 2030 Vision.
👇 Don’t forget to check out the first three parts in this series:
Part 1 – “Longevity Escape Velocity: The Race to Beat Aging by 2030″
Part 2 – “Longevity Escape Velocity 2025: Latest Research Uncovered!“
Part 3 – “Longevity Escape Velocity: How AI is making us immortal by 2030!”
📌 Easy Insight simplifies the future — from longevity breakthroughs to mind-bending AI and quantum revolutions.
🔍 KEYWORDS:
longevity, longevity escape velocity, AI, artificial intelligence, quantum computing, supercomputers, simplified science, easy insightm, CRISPR 2025, CRISPR gene editing, CRISPR cures diseases, CRISPR longevity, prime editing 2025, base editing 2025, AI in gene editing, gene editing breakthroughs, gene therapy 2025, life extension 2025, reversing aging with CRISPR, CRISPR diabetes cure, CRISPR cholesterol PCSK9, CRISPR ATTR amyloidosis, CRISPR medical revolution, Easy Insight longevity.
👇 JOIN THE CONVERSATION:
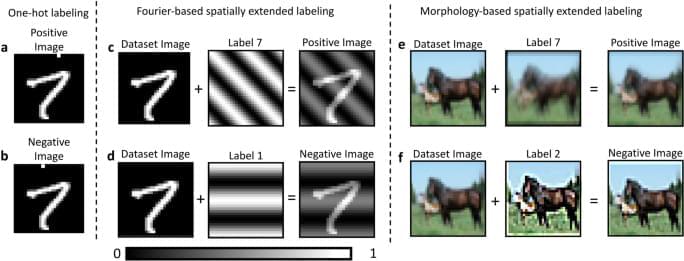
Training convolutional neural networks with the Forward–Forward Algorithm
Scodellaro, R., Kulkarni, A., Alves, F. et al. Training convolutional neural networks with the Forward–Forward Algorithm. Sci Rep 15, 38,461 (2025). https://doi.org/10.1038/s41598-025-26235-2


Stanford AI Experts Predict What Will Happen in 2026
After years of fast expansion and billion-dollar bets, 2026 may mark the moment artificial intelligence confronts its actual utility. In their predictions for the next year, Stanford faculty across computer science, medicine, law, and economics converge on a striking theme: The era of AI evangelism is giving way to an era of AI evaluation. Whether it’s standardized benchmarks for legal reasoning, real-time dashboards tracking labor displacement, or clinical frameworks for vetting the flood of medical AI startups, the coming year demands rigor over hype. The question is no longer “Can AI do this?” but “How well, at what cost, and for whom?”
Learn more about what Stanford HAI faculty expect in the new year.
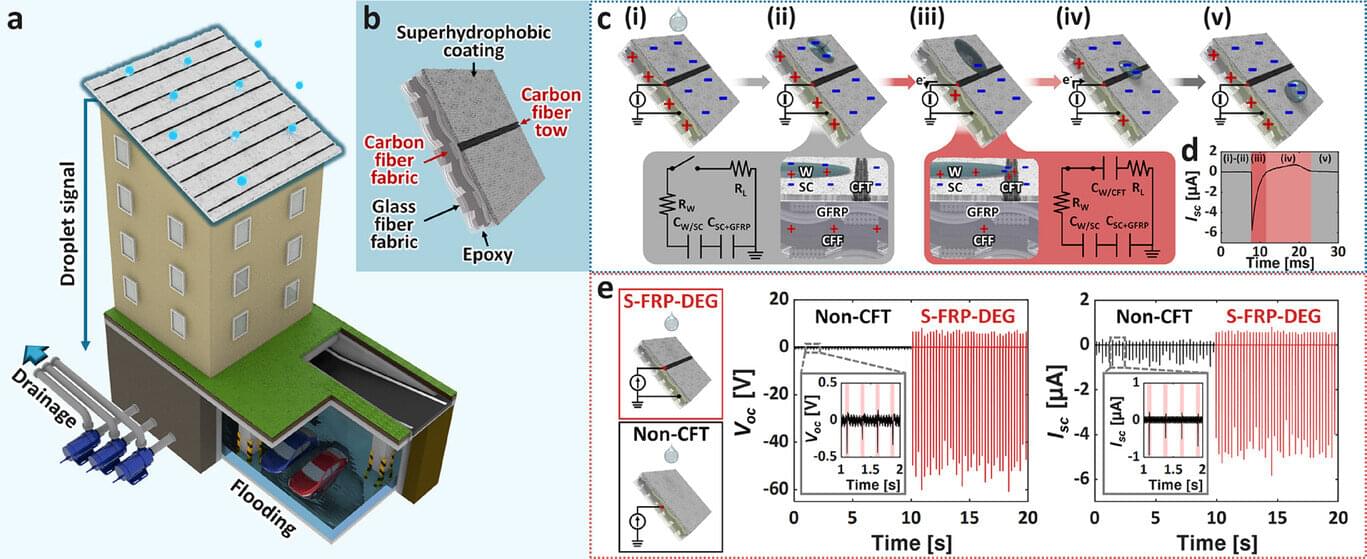
New generator uses carbon fiber to turn raindrops into rooftop electricity
A research team affiliated with UNIST has introduced a technology that generates electricity from raindrops striking rooftops, offering a self-powered approach to automated drainage control and flood warning during heavy rainfall.
Led by Professor Young-Bin Park of the Department of Mechanical Engineering at UNIST, the team developed a droplet-based electricity generator (DEG) using carbon fiber-reinforced polymer (CFRP). This device, called the superhydrophobic fiber-reinforced polymer (S-FRP-DEG), converts the impact of falling rain into electrical signals capable of operating stormwater management systems without an external power source. The findings are published in Advanced Functional Materials.
CFRP composites are lightweight, yet durable, and are used in a variety of applications, such as aerospace and construction because of their strength and resistance to corrosion. Such characteristics make it well suited for long-term outdoor installation on rooftops and other exposed urban structures.