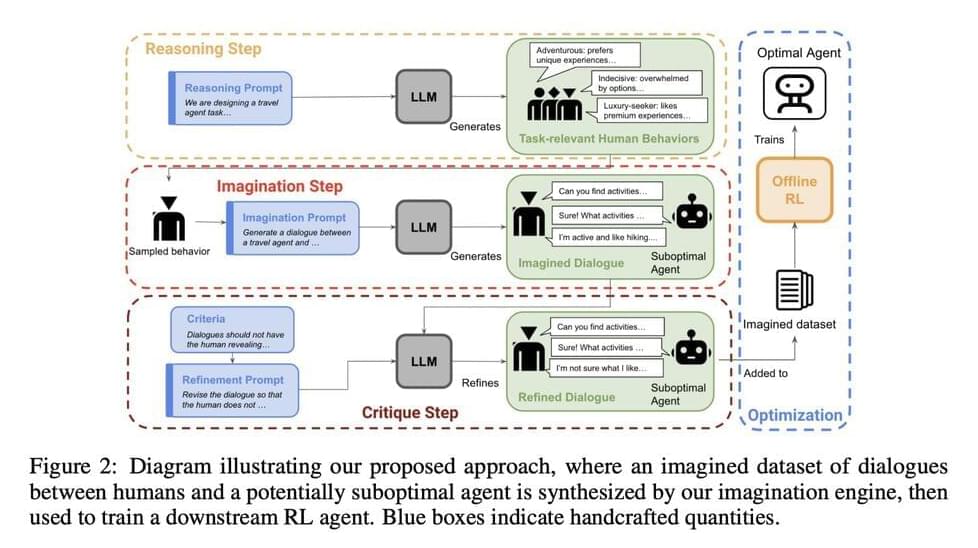
I suggest two responses to this difficult challenge for the United States and its allies: At the time of attack, the allies should respond with nonnuclear retaliation as long as politically feasible, in order to prevent further nuclear escalation. However, this will be difficult given the likely post-strike panic and hysteria. So, in preparation, the US should deconcentrate its northeast Asian conventional footprint, to reduce North Korean opportunities to engage in nuclear blackmail regarding regional American clusters of military equipment and personnel, and to reduce potential US casualties and consequent massive retaliation pressures if North Korea does launch a nuclear attack.
North Korean first-use incentives. The incentives for North Korea to use nuclear weapons first in a major conflict are powerful:
Operationally, North Korea will likely have only a very short time window to use its weapons of mass destruction. The Americans will almost certainly try to immediately suppress Northern missiles. An imminent, massive US-South Korea disarming strike creates an extreme use-it-or-lose-it dilemma for Pyongyang. If Kim Jong-Un does not use his nuclear weapons at the start of hostilities, most will be destroyed a short time later by allied airpower, turning an inter-Korean conflict into a conventional war that the North will probably lose. Frighteningly, this may encourage Kim to also release his strategic nuclear weapons almost immediately after fighting begins.




{kind=link}
{kind=link}