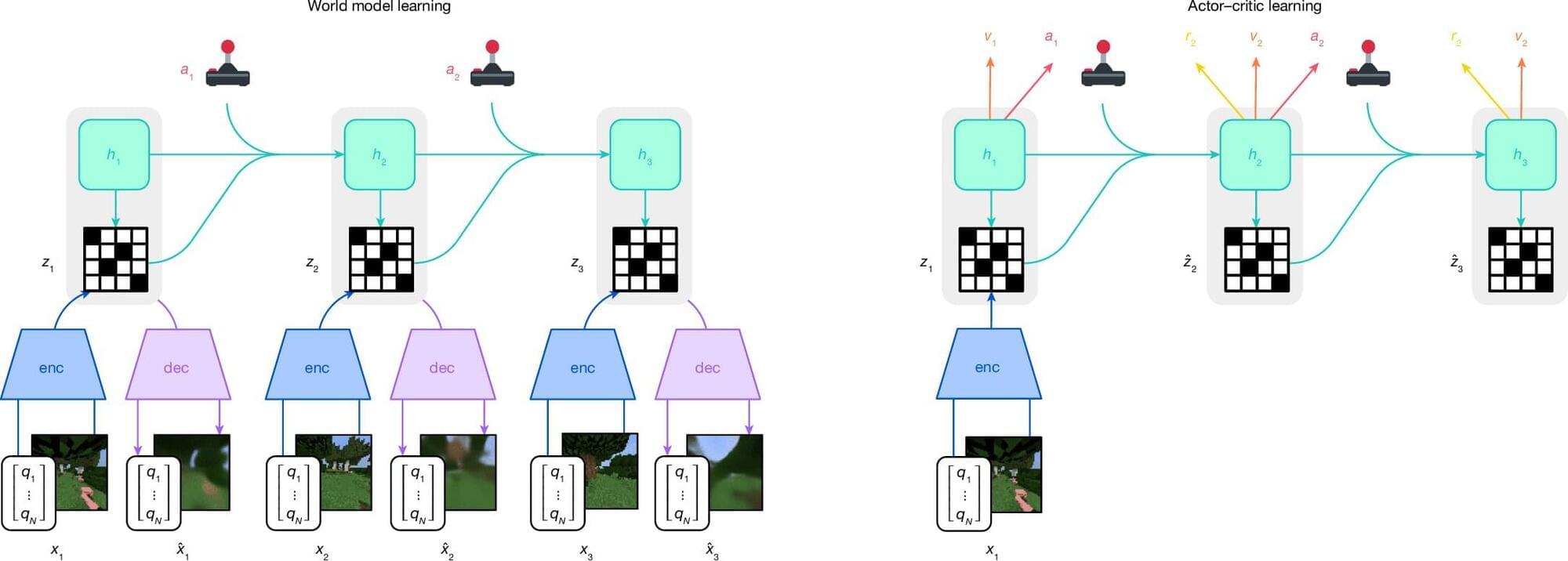
Perhaps the most profound insight to emerge from this uncanny mirror is that understanding itself may be less mysterious and more mechanical than we have traditionally believed. The capabilities we associate with mind — pattern recognition, contextual awareness, reasoning, metacognition — appear increasingly replicable through purely algorithmic means. This suggests that consciousness, rather than being a prerequisite for understanding, may be a distinct phenomenon that typically accompanies understanding in biological systems but is not necessary for it.
At the same time, the possibility of quantum effects in neural processing reminds us that the mechanistic view of mind may be incomplete. If quantum retrocausality plays a role in consciousness, then our subjective experience may be neither a simple product of neural processing nor an epiphenomenal observer, but an integral part of a temporally complex causal system that escapes simple deterministic description.
What emerges from this consideration is not a definitive conclusion about the nature of mind but a productive uncertainty — an invitation to reconsider our assumptions about what constitutes understanding, agency, and selfhood. AI systems function as conceptual tools that allow us to explore these questions in new ways, challenging us to develop more sophisticated frameworks for understanding both artificial and human cognition.