Walls are going up at Tesla’s Supercharger, diner and drive-in movie theater concept in Los Angeles, California, as shown in new footage.

In the adrenaline-fueled arena of sports gambling, a revolution is unfolding — one powered by artificial intelligence (AI). This technological marvel is transforming the art of sports betting from a game of chance into a symphony of data-driven precision. Let us explore the burgeoning world where AI intersects with sports gambling, turning bettors from mere spectators into strategic players in a game where data, algorithms, and probabilities redefine the odds.
Sports gambling, a realm where intuition, experience, and sometimes sheer luck have traditionally dictated the rules, is undergoing a transformative shift. AI, with its unparalleled ability to analyze vast datasets and discern patterns beyond human capability, is emerging as the new MVP in this field. This transition from gut-driven bets to AI-powered predictions is not just about increasing the odds of winning; it’s about elevating sports gambling to an art of calculated strategies.
At the heart of AI’s influence in sports gambling lies predictive analytics. Companies like Stratagem and Stats Perform are harnessing the power of AI to analyze historical data, player statistics, and even weather conditions to predict game outcomes with astonishing accuracy. For instance, Stratagem uses advanced machine learning algorithms to turn data from thousands of past games into insightful betting strategies, offering gamblers an edge that was unimaginable a few years ago.
“You want the robot to help others, not others, help the robot,” emphasized Peter Dend, product manager at DEEP Robotics, who dived into the future of Quadruped Robotics during a webinar conducted by Interesting Engineering.
In IE’s first webinar of 2024, a DEEP Robotics representative unveiled a series of robot models employed for various tasks in real time, such as the Robot-Group-Control Dance Show at the 19th Hangzhou Asian Games.
The firm highlighted its partnership with the Zhejiang Lab, which used coordinated group control technology to combine bipedal and quadruped robots to perform the Asian Games Village theme song “Love Together.”



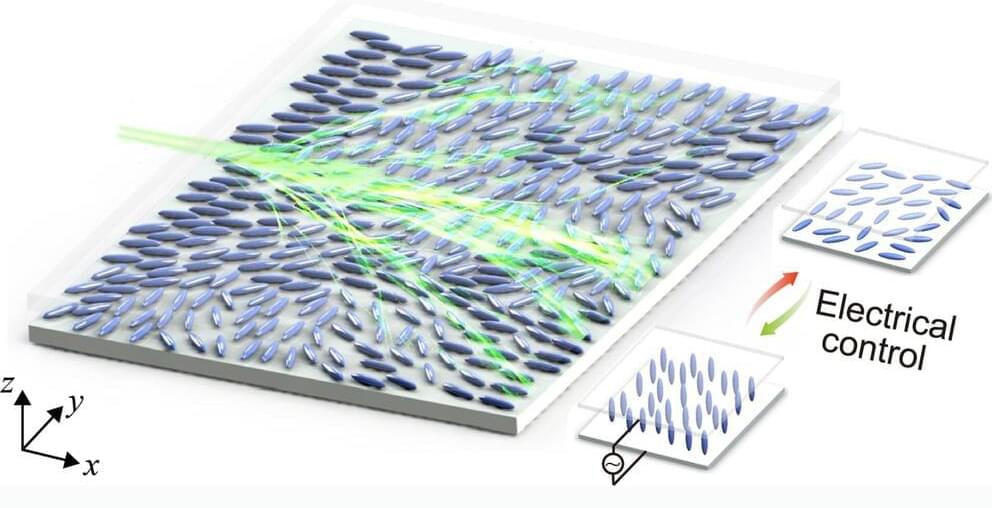
A new study in Nature Communications investigates the electrical tuning of branched light flow in nematic liquid crystal (NLC) films, revealing controlled patterns and statistical characteristics with potential applications in optics and photonics.
Branched light flow manifests as intricate patterns in light waves navigating through a disordered medium, forming multiple branching pathways.
Positioned between ballistic and diffusive transport phenomena—where ballistic implies unhindered straight-line movement akin to a laser beam, and diffusive involves scattered, chaotic behavior—the phenomenon gains significance for its potential in controlling physical processes, particularly optics, and photonics.

Companies like OpenAI and Midjourney have opened Pandora’s box, opening them up to considerable legal trouble by training their chatbots on the vastness of the internet while largely turning a blind eye to copyright.
As professor and author Gary Marcus and film industry concept artist Reid Southen, who has worked on several major films for the likes of Marvel and Warner Brothers, argue in a recent piece for IEEE Spectrum, tools like DALL-E 3 and Midjourney could land both companies in a “copyright minefield.”
It’s a heated debate that’s reaching fever pitch. The news comes after the New York Times sued Microsoft and OpenAI, alleging it was responsible for “billions of dollars” in damages by training ChatGPT and other large language models on its content without express permission. Well-known authors including “Game of Thrones” author George RR Martin and John Grisham recently made similar arguments in a separate copyright infringement case.

Valve has changed its policy and will now allow games made by AI, or that use AI generated content, to be sold on Steam.
Back in June, we shared that while our goal continues to be shipping as many games as possible on Steam, we needed some time to learn about the fast-moving and legally murky space of AI technology, especially given Steam’s worldwide reach. Today, after spending the last few months learning more about this space and talking with game developers, we are making changes to how we handle games that use AI technology. This will enable us to release the vast majority of games that use it.

In recent years, engineers have developed a wide range of robotic systems that could soon assist humans with various everyday tasks. Rather than assisting with chores or other manual jobs, some of these robots could merely act as companions, helping older adults or individuals with different disabilities to practice skills that typically entail interacting with another human.
Researchers at Nara Institute of Science and Technology in Japan recently developed a new robot that can play video games with a human user. This robot, introduced in a paper presented at the 11th International Conference on Human-Agent Interaction, can play games with users while communicating with them.
“We have been developing robots that can chat while watching TV together, and interaction technology that creates empathy, in order to realize a partner robot that can live together with people in their daily life,” Masayuki Kanbara, one of the researchers who carried out the study, told Tech Xplore. “In this paper, we developed a robot that plays TV games together to provide opportunities for people to interact with the robot in their daily lives.”
{kind=link}