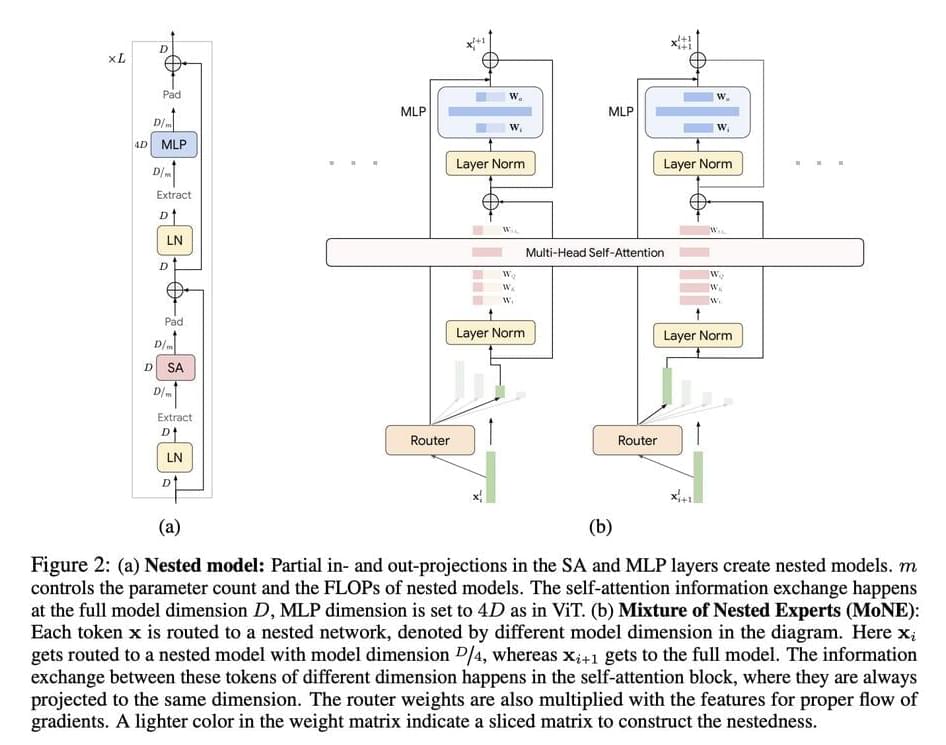
One of the significant challenges in AI research is the computational inefficiency in processing visual tokens in Vision Transformer (ViT) and Video Vision Transformer (ViViT) models. These models process all tokens with equal emphasis, overlooking the inherent redundancy in visual data, which results in high computational costs. Addressing this challenge is crucial for the deployment of AI models in real-world applications where computational resources are limited and real-time processing is essential.
Current methods like ViTs and Mixture of Experts (MoEs) models have been effective in processing large-scale visual data but come with significant limitations. ViTs treat all tokens equally, leading to unnecessary computations. MoEs improve scalability by conditionally activating parts of the network, thus maintaining inference-time costs. However, they introduce a larger parameter footprint and do not reduce computational costs without skipping tokens entirely. Additionally, these models often use experts with uniform computational capacities, limiting their ability to dynamically allocate resources based on token importance.