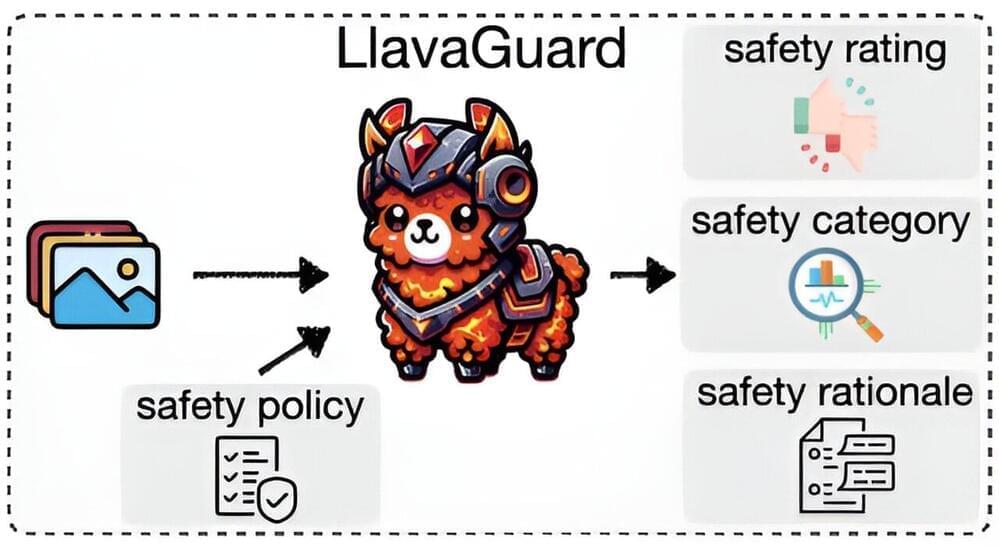
Researchers at the Artificial Intelligence and Machine Learning Lab (AIML) in the Department of Computer Science at TU Darmstadt and the Hessian Center for Artificial Intelligence (hessian. AI) have developed a method that uses vision language models to filter, evaluate, and suppress specific image content in large datasets or from image generators.
Artificial intelligence (AI) can be used to identify objects in images and videos. This computer vision can also be used to analyze large corpora of visual data.
Researchers led by Felix Friedrich from the AIML have developed a method called LlavaGuard, which can now be used to filter certain image content. This tool uses so-called vision language models (VLMs). In contrast to large language models (LLMs) such as ChatGPT, which can only process text, vision language models are able to process and understand image and text content simultaneously. The work is published on the arXiv preprint server.