There is a growing need to develop methods capable of efficiently processing and interpreting data from various document formats. This challenge is particularly pronounced in handling visually rich documents (VrDs), such as business forms, receipts, and invoices. These documents, often in PDF or image formats, present a complex interplay of text, layout, and visual elements, necessitating innovative approaches for accurate information extraction.
Traditionally, approaches to tackle this issue have leaned on two architectural types: transformer-based models inspired by Large Language Models (LLMs) and Graph Neural Networks (GNNs). These methodologies have been instrumental in encoding text, layout, and image features to improve document interpretation. However, they often need help representing spatially distant semantics essential for understanding complex document layouts. This challenge stems from the difficulty in capturing the relationships between elements like table cells and their headers or text across line breaks.
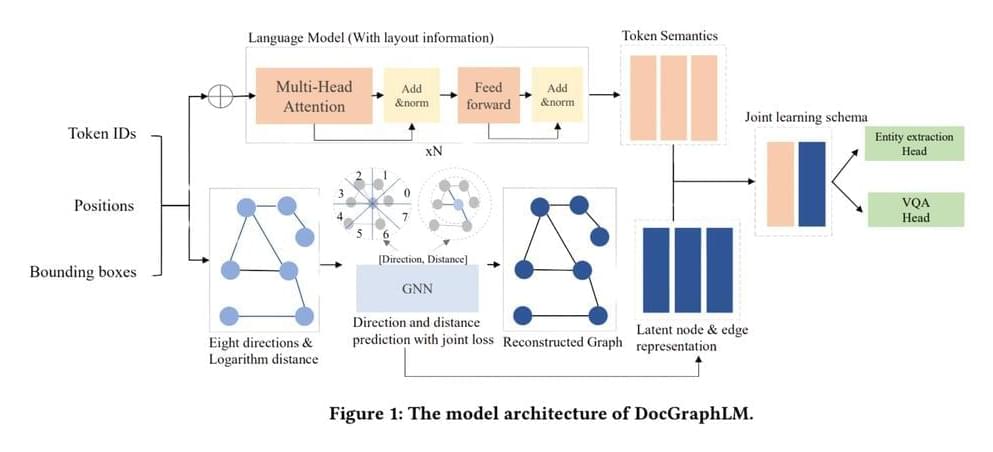
Researchers at JPMorgan AI Research and the Dartmouth College Hanover have innovated a novel framework named ‘DocGraphLM’ to bridge this gap. This framework synergizes graph semantics with pre-trained language models to overcome the limitations of current methods. The essence of DocGraphLM lies in its ability to integrate the strengths of language models with the structural insights provided by GNNs, thus offering a more robust document representation. This integration is crucial for accurately modeling visually rich documents’ intricate relationships and structures.