NVFi tackles the intricate challenge of comprehending and predicting the dynamics within 3D scenes evolving over time, a task critical for applications in augmented reality, gaming, and cinematography. While humans effortlessly grasp the physics and geometry of such scenes, existing computational models struggle to explicitly learn these properties from multi-view videos. The core issue lies in the inability of prevailing methods, including neural radiance fields and their derivatives, to extract and predict future motions based on learned physical rules. NVFi ambitiously aims to bridge this gap by incorporating disentangled velocity fields derived purely from multi-view video frames, a feat yet unexplored in prior frameworks.
The dynamic nature of 3D scenes poses a profound computational challenge. While recent advancements in neural radiance fields showcased exceptional abilities in interpolating views within observed time frames, they fall short in learning explicit physical characteristics such as object velocities. This limitation impedes their capability to foresee future motion patterns accurately. Current studies integrating physics into neural representations exhibit promise in reconstructing scene geometry, appearance, velocity, and viscosity fields. However, these learned physical properties are often intertwined with specific scene elements or necessitate supplementary foreground segmentation masks, limiting their transferability across scenes. NVFi’s pioneering ambition is to disentangle and comprehend the velocity fields within entire 3D scenes, fostering predictive capabilities extending beyond training observations.
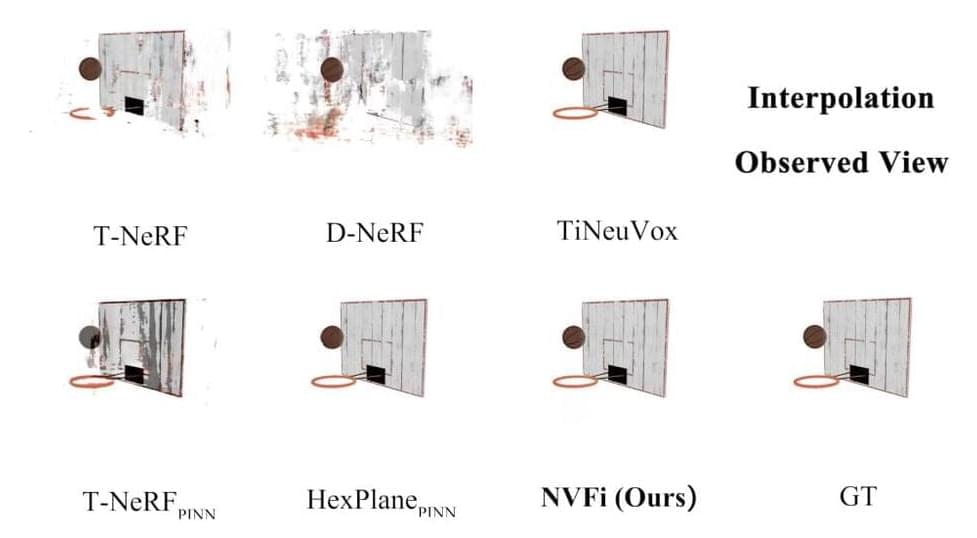
Researchers from The Hong Kong Polytechnic University introduce a comprehensive framework NVFi encompassing three fundamental components. First, a keyframe dynamic radiance field facilitates the learning of time-dependent volume density and appearance for every point in 3D space. Second, an interframe velocity field captures time-dependent 3D velocities for each point. Finally, a joint optimization strategy involving both keyframe and interframe elements, augmented by physics-informed constraints, orchestrates the training process. This framework offers flexibility in adopting existing time-dependent NeRF architectures for dynamic radiance field modeling while employing relatively simple neural networks, such as MLPs, for the velocity field. The core innovation lies in the third component, where the joint optimization strategy and specific loss functions enable precise learning of disentangled velocity fields without additional object-specific information or masks.