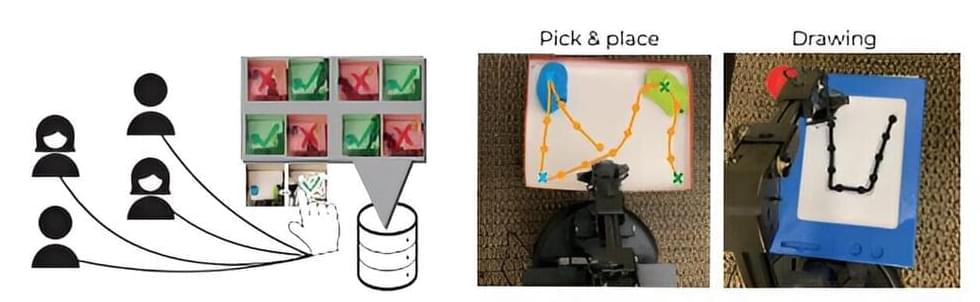
To teach an AI agent a new task, like how to open a kitchen cabinet, researchers often use reinforcement learning—a trial-and-error process where the agent is rewarded for taking actions that get it closer to the goal.
In many instances, a human expert must carefully design a reward function, which is an incentive mechanism that gives the agent motivation to explore. The human expert must iteratively update that reward function as the agent explores and tries different actions. This can be time-consuming, inefficient, and difficult to scale up, especially when the task is complex and involves many steps.
Researchers from MIT, Harvard University, and the University of Washington have developed a new reinforcement learning approach that doesn’t rely on an expertly designed reward function. Instead, it leverages crowdsourced feedback, gathered from many non-expert users, to guide the agent as it learns to reach its goal. The work has been published on the pre-print server arXiv.