In the field of artificial intelligence, reinforcement learning is a type of machine-learning strategy that rewards desirable behaviors while penalizing those which aren’t. An agent can perceive its surroundings and act accordingly through trial and error in general with this form or presence – it’s kind of like getting feedback on what works for you. However, learning rules from scratch in contexts with complex exploration problems is a big challenge in RL. Because the agent does not receive any intermediate incentives, it cannot determine how close it is to complete the goal. As a result, exploring the space at random becomes necessary until the door opens. Given the length of the task and the level of precision required, this is highly unlikely.
Exploring the state space randomly with preliminary information should be avoided while performing this activity. This prior knowledge aids the agent in determining which states of the environment are desirable and should be investigated further. Offline data collected by human demonstrations, programmed policies, or other RL agents could be used to train a policy and then initiate a new RL policy. This would include copying the pre-trained policy’s neural network to the new RL policy in the scenario where we utilize neural networks to describe the procedures. This process transforms the new RL policy into a pre-trained one. However, as seen below, naively initializing a new RL policy like this frequently fails, especially for value-based RL approaches.
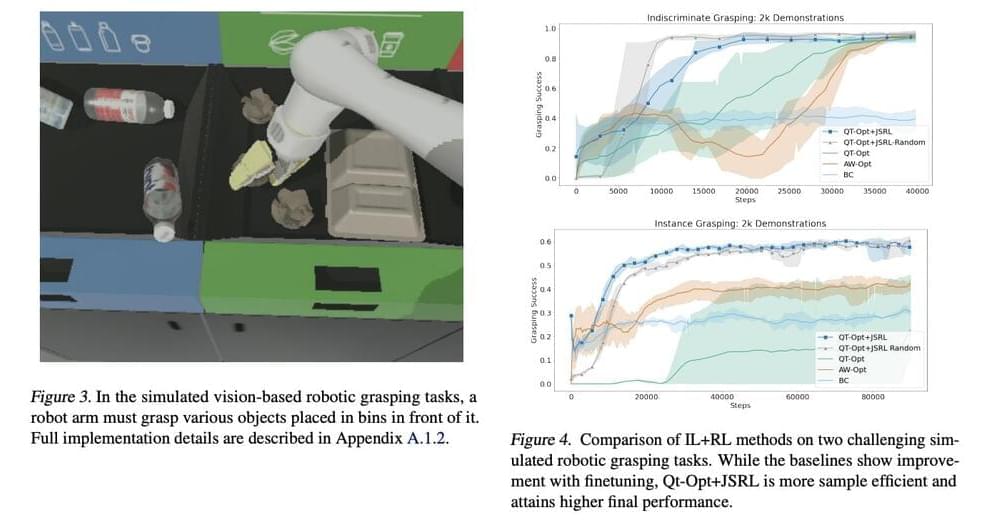
Google AI researchers have developed a meta-algorithm to leverage pre-existing policy to initialize any RL algorithm. The researchers utilize two procedures to learn tasks in Jump-Start Reinforcement Learning (JSRL): a guide policy and an exploration policy. The exploration policy is an RL policy trained online using the agent’s new experiences in the environment. In contrast, the guide policy is any pre-existing policy that is not modified during online training. JSRL produces a learning curriculum by incorporating the guide policy, followed by the self-improving exploration policy, yielding results comparable to or better than competitive IL+RL approaches.