With artificial intelligence (AI) tools and machine learning algorithms now making their way into a wide variety of settings, assessing their security and ensuring that they are protected against cyberattacks is of utmost importance. As most AI algorithms and models are trained on large online datasets and third-party databases, they are vulnerable to a variety of attacks, including neural Trojan attacks.
A neural Trojan attack occurs when an attacker inserts what is known as a hidden Trojan trigger or backdoor inside an AI model during its training. This trigger allows the attacker to hijack the model’s prediction at a later stage, causing it to classify data incorrectly. Detecting these attacks and mitigating their impact can be very challenging, as a targeted model typically performs well and in alignment with a developer’s expectations until the Trojan backdoor is activated.
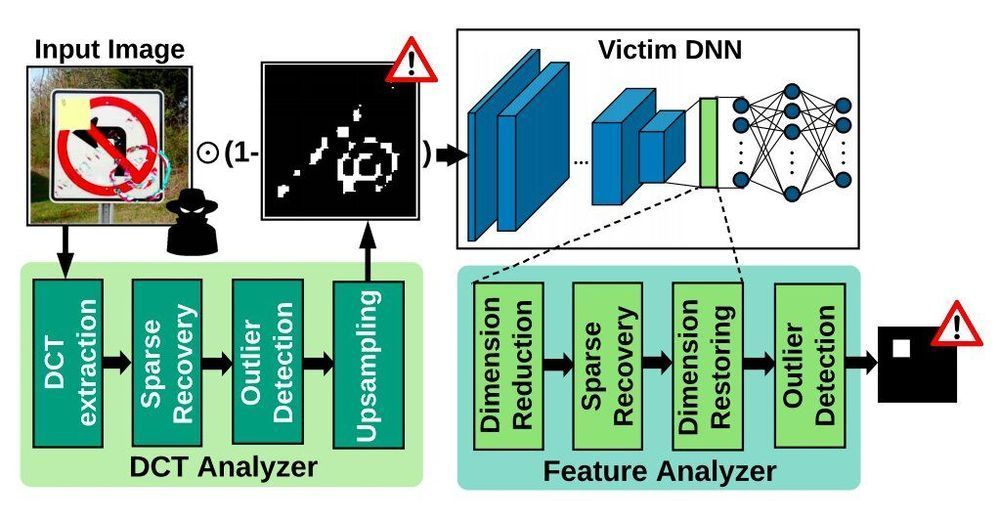
Researchers at University of California, San Diego have recently created CLEANN, an end-to-end framework designed to protect embedded artificial neural networks from Trojan attacks. This framework, presented in a paper pre-published on arXiv and set to be presented at the 2020 IEEE/ACM International Conference on Computer-Aided Design, was found to perform better than previously developed Trojan shields and detection methods.