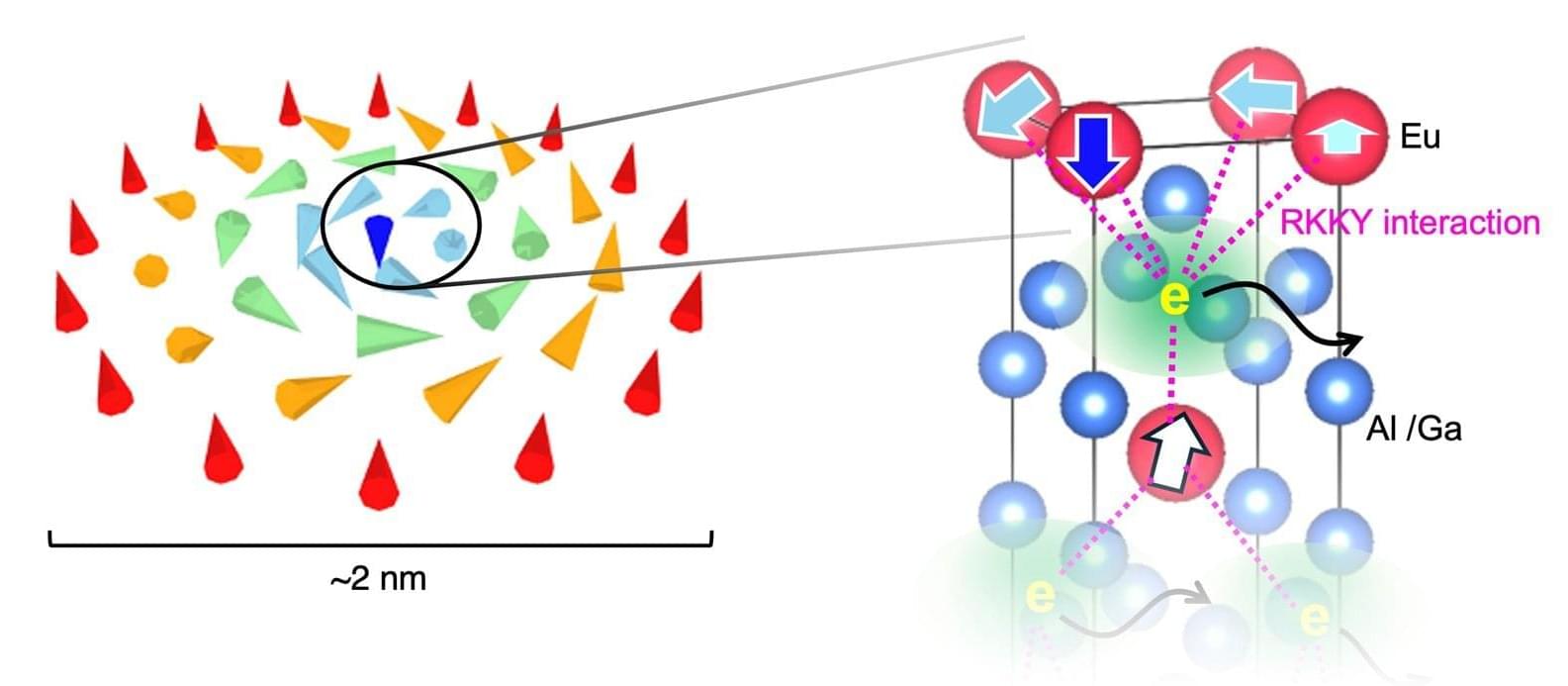
When looking to the future of information technology, researchers have pinpointed a once-theoretical particle-like structure: the skyrmion. Magnetic skyrmions are very stable structures found on micromagnetic materials that have a vortex-like spin. Because they can be moved with minimal electrical current, these structures could help develop memory to power the next generation of computing without consuming a lot of power.
But until recently, the fundamental properties of the skyrmion remained a mystery to researchers. In a paper published in Nature Communications, researchers shared new details and properties about these structures.
“Skyrmions are highly stable and move with minimal electrical current, paving the way for next-generation memory with extremely low power consumption. It’s the ultimate miniaturization, utilizing ‘world-class’ 2-nanometer structures that will allow ultra-high-density data storage and much smaller electronic devices,” said Kosuke Nakayama, a professor at Tohoku University in Sendai, Japan.





{kind=link}