The AI algorithm is more efficient in distinguishing false positives from the real stuff than human experts.
A new artificial intelligence algorithm has discovered over 300 previously unknown exoplanets in data gathered by a now-defunct exoplanet-hunting telescope.
The Kepler Space Telescope, NASA’s first dedicated exoplanet hunter, has observed hundreds of thousands of stars in the search for potentially habitable worlds outside our solar system. The calatog of potential planets it had compiled continues generating new discoveries even after the telescope’s demise. Human experts analyze the data for signs of exoplanets. But a new algorithm called ExoMiner can now mimic that procedure and scour the catalog faster and more efficiently.
When people think of artificial intelligence, the images that often come to mind are of the sinister robots that populate the worlds of “The Terminator,” “i, Robot,” “Westworld,” and “Blade Runner.” For many years, fiction has told us that AI is often used for evil rather than for good.
But what we may not usually associate with AI is art and poetry — yet that’s exactly what Ai-Da, a highly realistic robot invented by Aidan Meller in Oxford, central England, spends her time creating. Ai-Da is the world’s first ultra-realistic humanoid robot artist, and on Friday she gave a public performance of poetry that she wrote using her algorithms in celebration of the great Italian poet Dante.
The recital took place at the University of Oxford’s renowned Ashmolean Museum as part of an exhibition marking the 700th anniversary of Dante’s death. Ai-Da’s poem was produced as a response to the poet’s epic “Divine Comedy” — which Ai-Da consumed in its entirety, allowing her to then use her algorithms to take inspiration from Dante’s speech patterns, and by using her own data bank of words, create her own work.
Everything we do as living organisms is dependent, in some capacity, on time. The concept is so complex that scientists still argue whether it exists or if it is an illusion. In this video, astrophysicist Michelle Thaller, science educator Bill Nye, author James Gleick, and neuroscientist Dean Buonomano discuss how the human brain perceives of the passage of time, the idea in theoretical physics of time as a fourth dimension, and the theory that space and time are interwoven. Thaller illustrates Einstein’s theory of relativity, Buonomano outlines eternalism, and all the experts touch on issues of perception, definition, and experience. Check Dean Buonomano’s latest book Your Brain Is a Time Machine: The Neuroscience and Physics of Time at https://amzn.to/2GY1n1z.
TRANSCRIPT: MICHELLE THALLER: Is time real or is it an illusion? Well, time is certainly real but the question is what do we mean by the word time? And it may surprise you that physicists don’t have a simple answer for that. JAMES GLEICK: Physicists argue about and physicists actually have symposia on the subject of is there such a thing as time. And it’s also something that has a traditional in philosophy going back about a century. But, I think it’s fair to say that in one sense it’s a ridiculous idea. How can you say time doesn’t exist when we have such a profound experience of it first of all. And second of all we’re talking about it constantly. I mean we couldn’t get, I can’t get through this sentence with out referring to time. I was going to say we couldn’t get through the day without discussing time. So, obviously when a physicist questions the existence of time they are trying to say something specialized, something technical. BILL NYE: Notice that in English we don’t have any other word for time except time. It’s unique. It’s this wild fourth dimension in nature. This is one dimension, this is one dimension, this is one dimension and time is the fourth dimension. And we call it the fourth dimension not just in theoretical physics but in engineering. I worked on four dimensional autopilots so you tell where you want to go and what altitude it is above sea level and then when you want to get there. Like you can’t get there at any time. GLEICK: Einstein or maybe I should say more properly Minkowski, his teacher and contemporary, offers a vision of space-time as a single thing, as a four dimensional block in which the past and the future are just like spatial dimensions. They’re just like north and south in the equations of physics. And so you can construct a view of the world in which the future is already there and you can say, and physicists do say something very much like this, that in the fundamental laws of physics there is no distinction between the past and the future. And so if you’re playing that game you’re essentially saying time as an independent thing doesn’t exist. Time is just another dimension like space. Again, that is in obvious conflict with our intuitions about the world. We go through the day acting as though the past is over and the future has not yet happened and it might happen this way or it might happen that way. We could flip a coin and see. We tend to believe in our gut that the future is not fully determined and therefore is different from the past. DEAN BUONOMANO: If the flow if time, if our subjective sense of the flow of time is an illusion we have this clash between physics and neuroscience because the dominant theory in physics is that we live in the block universe. And I should be clear. There’s no consensus. There’s no 100 percent agreement. But the standard view in physics is that, and this comes in large part from relativity, that we live in an eternalist universe, in a block universe in which the past, present and future is equally real. So, this raises the question of whether we can trust our brain to tell us that time is flowing. NYE: In my opinion time is both subjective and objective. What we do in science and engineering and in life, astronomy, is measure time as carefully as we can because it’s so important to our everyday world. You go to plant crops you want to know when to plant them. You want to know when to harvest them. If you want to have a global positioning system that enables you to determine which side of the street you’re on, from your phone you need to take into account both the traditional passage of time that you might be familiar with watching a clock here on the Earth’s surface, and the passage of time as it’s affected by the… Read the full transcript at https://bigthink.com/videos/does-time-exist
Women constitute a mere 22 per cent or less than a quarter of professionals in the field of AI and Data Science.
There is a troubling and persistent absence of women when it comes to the field of artificial intelligence and data science. Women constitute a mere 22 per cent or less than a quarter of professionals in this field, as says the report “Where are the women? Mapping the gender job gap in AI,” from The Turing Institute. Yet, despite low participation and obstacles, women are breaking the silos and setting an example for players out in the field of AI.
To honour their commitment and work done, we have listed some of the women innovators and researchers who have worked tirelessly and contributed significantly to the field of AI and data science. The list below is provided in no particular order.
The brainchild behind and the founder of The Algorithmic Justice League (AJL), Joy Buolamwini, has started the organisation that combines art and research to illuminate the social implications and harms of artificial intelligence. With her pioneering work on algorithmic bias, Joy opened the eyes of the world and brought out the gender bias and racial prejudices embedded in facial recognition systems. As a result, Amazon, Microsoft, and IBM all halted their facial recognition services, admitting that the technology was not yet ready for widespread usage. One can watch the famous documentary ‘Coded Bias’ to understand her work. Her contributions will surely pave the way for a more inclusive and diversified AI community in the near future.
Scientists have been able to trap antimatter particles using a combination of electric and magnetic fields. Antiprotons have been stored for over a year, while antimatter electrons have been stored for shorter periods of time, due to their lower mass. In 2011, researchers at CERN announced that they had stored antihydrogen for over 1,000 seconds.
While scientists have been able to store and manipulate small quantities of antimatter, they have not been able to answer why antimatter is so rare in the universe. According to Einstein’s famous equation E = mc2, energy should convert into matter and antimatter in equal quantities. And, immediately after the Big Bang, there was a lot of energy. Accordingly, we should see as much antimatter as matter in our universe, and yet we don’t. This is a pressing unsolved mystery of modern physics.
According to Einstein’s equations, as well as other modern theories of antimatter, antimatter should be exactly the same as ordinary matter, with only the electric charges reversed. Thus, antimatter hydrogen should emit light just like ordinary hydrogen does, and with exactly the same wavelengths. In fact, an experiment showing exactly this behavior was reported in early 2020. This was a triumph for current theories, but meant no explanation for the universe’s preference of matter was found.
To address the growing threat of cyberattacks on industrial control systems, a KAUST team including Fouzi Harrou, Wu Wang and led by Ying Sun has developed an improved method for detecting malicious intrusions.
Internet-based industrial control systems are widely used to monitor and operate factories and critical infrastructure. In the past, these systems relied on expensive dedicated networks; however, moving them online has made them cheaper and easier to access. But it has also made them more vulnerable to attack, a danger that is growing alongside the increasing adoption of internet of things (IoT) technology.
Conventional security solutions such as firewalls and antivirus software are not appropriate for protecting industrial control systems because of their distinct specifications. Their sheer complexity also makes it hard for even the best algorithms to pick out abnormal occurrences that might spell invasion.
Topic: Negative Energy, Quantum Information and Causality. Speaker: Adam Levine. Date: November 19, 2021
Einstein’s equations of gravity show that too much negative energy can lead to causality violations and causal paradoxes such as the so-called “grandfather paradox. In quantum mechanics, however, negative energies can arise from intrinsically quantum effects, such as the Casimir effect. Thus, it is not clear that gravity and quantum mechanics can be self-consistently combined. In this talk, Levine will discuss modern advances in understanding the connection between energy and causality in gravity and how quantum gravity avoids obvious paradoxes. He will also explore how this line of thought leads to new insights in quantum field theory, which governs particle physics.
As a physicist, Adam Levine’s research aims to understand the structure of entanglement in quantum field theories and quantum gravity through use of techniques from the study of conformal field theories, as well as quantum information theory and AdS/CFT. With support from the National Science Foundation, Adam is a long term Member in the School of Natural Sciences. He received his Ph.D. from University of California, Berkeley (2019), was a Graduate Fellow at the Kavli Institute for Theoretical Physics (2018), a National Defense Science and Engineering Graduate Fellow (2017−2020), and received the Jeffrey Willick Memorial Award for Outstanding Scholarship in Astrophysics from Stanford University (2015).
You are on the PRO Robots channel and in this video we will talk about artificial intelligence. Repeating brain structure, mutual understanding and mutual assistance, self-learning and rethinking of biological life forms, replacing people in various jobs and cheating. What have neural networks learned lately? All new skills and superpowers of artificial intelligence-based systems in one video!
0:00 In this video. 0:26 Isomorphic Labs. 1:14 Artificial intelligence trains robots. 2:01 MIT researchers’ algorithm teaches robots social skills. 2:45 AI adopts brain structure. 3:28 Revealing cause and effect relationships. 4:40 Miami Herald replaces fired journalist with bot. 5:26 Nvidia unveiled a neural network that creates animated 3D face models based on voice. 5:55 Sber presented code generation model based on ruGPT-3 neural network. 6:50 ruDALL-E multimodal neural network. 7:16 Cristofari Neo supercomputer for neural network training.
Architecture and construction have always been, rather quietly, at the bleeding edge of tech and materials trends. It’s no surprise, then, especially at a renowned technical university like ETH Zurich, to find a project utilizing AI and robotics in a new approach to these arts. The automated design and construction they are experimenting with show how homes and offices might be built a decade from now.
The project is a sort of huge sculptural planter, “hanging gardens” inspired by the legendary structures in the ancient city of Babylon. (Incidentally, it was my ancestor, Robert Koldewey, who excavated/looted the famous Ishtar Gate to the place.)
Begun in 2019, Semiramis (named after the queen of Babylon back then) is a collaboration between human and AI designers. The general idea of course came from the creative minds of its creators, architecture professors Fabio Gramazio and Matthias Kohler. But the design was achieved by putting the basic requirements, such as size, the necessity of watering and the style of construction, through a set of computer models and machine learning algorithms.
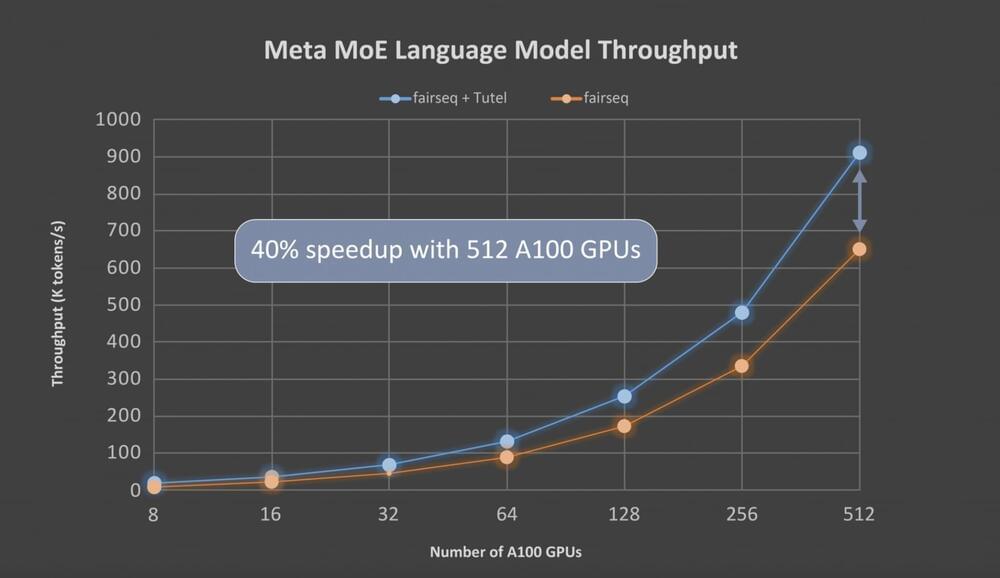
Tutel is a high-performance MoE library developed by Microsoft researchers to aid in the development of large-scale DNN (Deep Neural Network) models; Tutel is highly optimized for the new Azure NDm A100 v4 series, and Tutel’s diverse and flexible MoE algorithmic support allows developers across AI domains to execute MoE more easily and efficiently. Tutel achieves an 8.49x speedup on an NDm A100 v4 node with 8 GPUs and a 2.75x speedup on 64 NDm A100 v4 nodes with 512 A100 GPUs compared to state-of-the-art MoE implementations like Meta’s Facebook AI Research Sequence-to-Sequence Toolkit (fairseq) in PyTorch for a single MoE layer.
Tutel delivers a more than 40% speedup for Meta’s 1.1 trillion–parameter MoE language model with 64 NDm A100 v4 nodes for end-to-end performance, thanks to optimization for all-to-all communication. When working on the Azure NDm A100 v4 cluster, Tutel delivers exceptional compatibility and comprehensive capabilities to assure outstanding performance. Tutel is free and open-source software that has been integrated into fairseq.
Tutel is a high-level MoE solution that complements existing high-level MoE solutions like fairseq and FastMoE by focusing on the optimizations of MoE-specific computation and all-to-all communication and other diverse and flexible algorithmic MoE supports. Tutel features a straightforward user interface that makes it simple to combine with other MoE systems. Developers can also use the Tutel interface to include independent MoE layers into their own DNN models from the ground up, taking advantage of the highly optimized state-of-the-art MoE features right away.