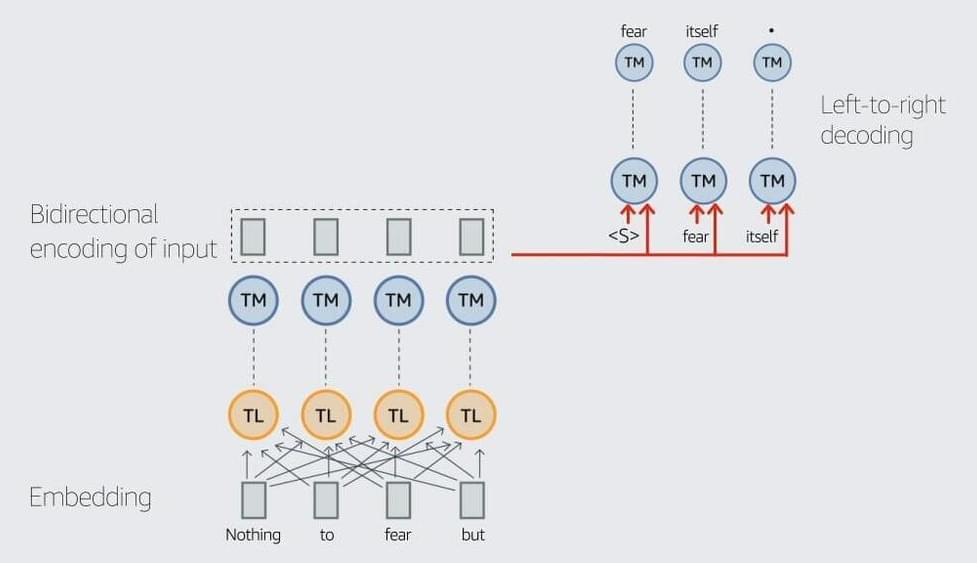
To train AlexaTM 20B, we break with convention, training on a mix of denoising and causal-language-modeling (CLM) tasks. On the denoising task, the model is required to find dropped spans and generate the complete version of the input. This is similar to how other seq2seq models like T5 and BART are trained. On the CLM task, the model is required to meaningfully continue the input text. This is similar to how decoder-only models like GPT-3 and PaLM are trained.
Training on a mix of these two pretraining tasks enables AlexaTM 20B to generalize based on the given input and generate new text (the CLM task), while also performing well on tasks that seq2seq models are particularly good at, such as summarization and machine translation (the denoising task).
For example, we demonstrated that, given a single article-summarization pair, AlexaTM 20B can generate higher-quality summaries in English, German, and Spanish than the much larger PaLM 540B can (see example, below).