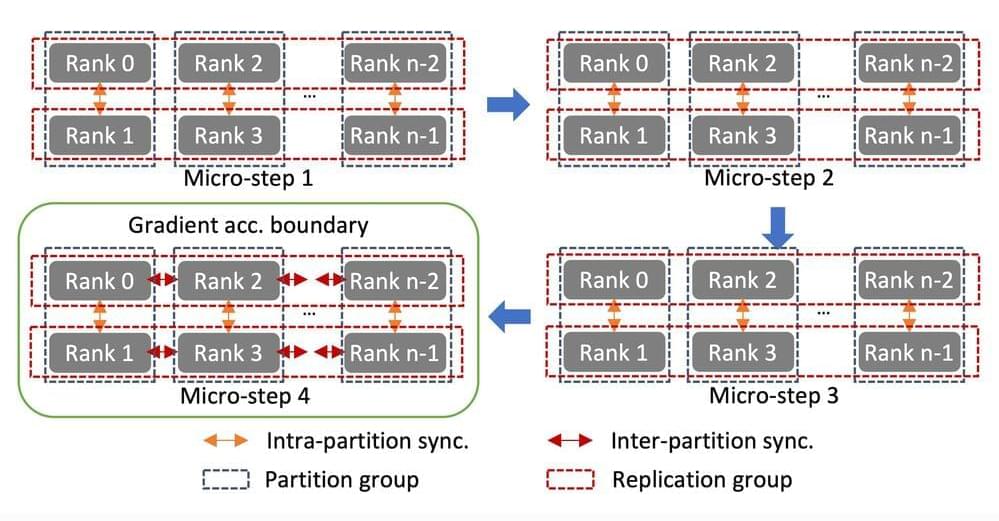
Linear scaling is often difficult to achieve because the communication required to coordinate the work of the cluster nodes eats into the gains from paralleliza… See more.
A new distributed-training library achieves near-linear efficiency in scaling from tens to hundreds of GPUs.