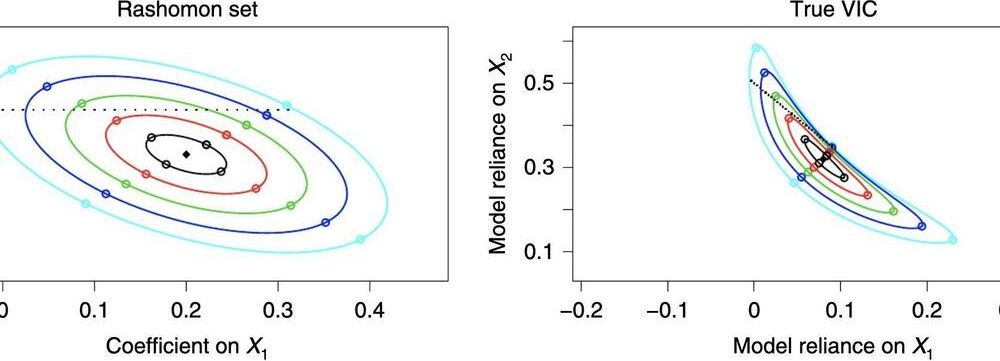
Two researchers at Duke University have recently devised a useful approach to examine how essential certain variables are for increasing the reliability/accuracy of predictive models. Their paper, published in Nature Machine Intelligence, could ultimately aid the development of more reliable and better performing machine-learning algorithms for a variety of applications.
“Most people pick a predictive machine-learning technique and examine which variables are important or relevant to its predictions afterwards,” Jiayun Dong, one of the researchers who carried out the study, told TechXplore. “What if there were two models that had similar performance but used wildly different variables? If that was the case, an analyst could make a mistake and think that one variable is important, when in fact, there is a different, equally good model for which a totally different set of variables is important.”
Dong and his colleague Cynthia Rudin introduced a method that researchers can use to examine the importance of variables for a variety of almost-optimal predictive models. This approach, which they refer to as “variable importance clouds,” could be used to gain a better understanding of machine-learning models before selecting the most promising to complete a given task.